
Tạo 1 tool scan subdomains đơn giản với Python
Bài đăng này đã không được cập nhật trong 6 năm
Scan subdomains là một trong những giai đoạn thu thập thông tin kiểm thử. Việc thực hiện tìm kiếm các subdomains bằng tay đôi khi gặp nhiều khó khăn, nên trong bài này mình sẽ hướng dẫn viết công cụ để giúp việc này dễ dàng hơn.
Cài đặt thư việc requests trong python:
pip install requests
Về cách triển khai trong bài này là brute-forcing, chúng ta sẽ thử tất cả các subdomains nằm trong wordlist bất cứ khi nào nhận được phản hồi thì đó là một subdomain hợp lệ. Đôi khi việc scan không ra được hết tất cả các subdomains, điều này là hoàn toàn bình thường bởi vì thư viện của chúng ta không chứa tất cả subdomains hợp lệ của target đó.
Import các thư viện cần thiết:
import requests
import urllib3
import sys
import threading
from queue import Queue
d = Queue()
- requests dùng để gửi yêu cầu đến
targetvà nhận viết domain đấy có hợp lệ hay không. - urllib3 để format
target. - threading thực hiện việc chạy đa luồng giúp cho chương trình nhanh hơn.
- queue thuận tiện hơn trong việc chạy đa luồng.
Xử lý target:
def parse_url(url):
try:
host = urllib3.util.url.parse_url(url).host
except Exception as e:
print("Invalid domain, try again..")
sys.exit(1)
return host
Hàm này cố gắng xử lý input để lấy hostname nếu như không hợp lệ chương trình sẽ tự động thoát.
def parse_wordlist(wordlist):
try:
wordlists = open(wordlist).read().splitlines()
except Exception as e:
print(e)
sys.exit(1)
return wordlists
Hàm này giúp chúng ta đọc tất cả các subdomains từ wordlist, với hàm splitlines() trong python sẽ giúp tách tất cả các dòng trong một chuỗi. Việc này giúp tránh trường hợp không thể load được wordlist gây ra lỗi chương trình, phải đảm bảo rằng bạn đã chọn đúng đường dẫn của file wordlist. Bạn có thể tham khảo một số wordlist về DNS trên Google, Github...
Sau đây là một trong những hàm chính của chương trình:
def scan_subdomain(target):
global d
while True:
subdomain = d.get()
url = f"http://{subdomain}.{target}"
try:
res = requests.get(url)
except requests.ConnectionError:
pass
else:
if res.status_code == 200:
print("[+] ", url)
d.task_done()
Để biết subdomains đó có hợp lệ hay không thì chúng ta sẽ gửi một requests đến domain đó, bất cứ khi nào nhận được phản hồi thì đó là hợp lệ. Khai báo một biến global queue để get các subdomains đã lưu trong queue, lặp cho đến khi tất cả các subdomains được thực hiện request, tạo một url với phần subdomain lấy từ queue và target mà ta nhắm đến, thực hiện việc gửi requests đến url đó và nhận kết quả phản hồi để xử lý. Nếu không thể Connect tới url đó thì bỏ qua và không in gì cả vì subdomains đó không hợp lệ, nếu nhận được status code là 200 tức là ta có thể kết nối đến subdomain đó và ta hoàn toàn có thể in ra vì nó hoàn toàn hợp lệ.
Với các chương trình scan việc chạy đơn luồng là khá chậm, đối với những word list lớn thì đơn luồng có thể chạy mất một ngày, để có thể cải thiện việc này bạn có thể tham khảo thêm về đa luồng.
def mutil_scan_subdomains(target,number_threads,subdomains):
global d
for subdomain in subdomains:
d.put(subdomain)
for thread in range(number_threads):
t = threading.Thread(target=scan_subdomain, args=(target,))
t.daemon = True
t.start()
Trước tiên thêm tất cả các subdomain từ wordlist đã được xử lý trước đó và put vào queue:
for subdomain in subdomains:
d.put(subdomain)
Sau đó khởi tạo và chạy với số luồng mà input nhập vào:
for thread in range(number_threads):
t = threading.Thread(target=scan_subdomain, args=(target,))
t.daemon = True
t.start()
main
def main():
target = input("Target: ")
wordlist = input("Wordlist: ")
number_threads = int(input("Number threads: "))
print("=====================")
mutil_scan_subdomains(target=target, number_threads=number_threads,subdomains=parse_wordlist(wordlist))
Với hàm main thì chỉ cần lấy các input truyền vào và chạy.
python scansubdoamin.py
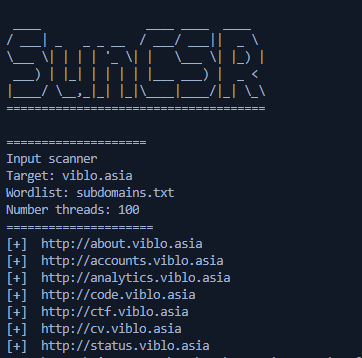
Target: viblo.asia
Wordlist: subdomains.txt
Number threads: 100
Đây là kết quả khi chạy:
Full code:
import requests
import urllib3
import sys
import threading
from queue import Queue
d = Queue()
def parse_url(url):
try:
host = urllib3.util.url.parse_url(url).host
except Exception as e:
print("Invalid domain, try again..")
sys.exit(1)
return host
def parse_wordlist(wordlist):
try:
wordlists = open(wordlist).read().splitlines()
except Exception as e:
print(e)
sys.exit(1)
return wordlists
def banner():
print('''
____ ____ ____ ____
/ ___| _ _ _ __ / ___/ ___|| _ \
\___ \| | | | '_ \| | \___ \| |_) |
___) | |_| | | | | |___ ___) | _ <
|____/ \__,_|_| |_|\____|____/|_| \_\
=====================================
''')
def scan_subdomain(target):
global d
while True:
subdomain = d.get()
url = f"http://{subdomain}.{target}"
try:
res = requests.get(url)
except requests.ConnectionError:
pass
else:
if res.status_code == 200:
print("[+] ", url)
d.task_done()
def mutil_scan_subdomains(target,number_threads,subdomains):
for subdomain in subdomains:
d.put(subdomain)
for thread in range(number_threads):
t = threading.Thread(target=scan_subdomain, args=(target,))
t.daemon = True
t.start()
def main():
target = input("Target: ")
wordlist = input("Wordlist: ")
number_threads = int(input("Number threads: "))
print("=====================")
mutil_scan_subdomains(target=target, number_threads=number_threads,subdomains=parse_wordlist(wordlist))
if __name__ == "__main__":
banner()
print("====================")
main()
d.join()
All rights reserved
