Một số thuật toán tối ưu trong DeepLearning
Bài đăng này đã không được cập nhật trong 2 năm
Vài lời bộc bạch
Đây là lần đầu tiên mình viết những bài viết mở và public như vậy, nếu như bài viết có bất cứ sai sót, hay góp ý gì cứ thì đừng ngại nói cho mình biết trong phần bình luận để mình sửa nhé. Chúc mọi người đọc vui vẻ
Gradient decent (GD)
Gradient decent là một thuật toán cơ bản trong machine learning nói chung và deep learning nói riêng để tối ưu các tham số cho mô hình học máy. Ý tưởng cơ bản nhất của gradient decent là dựa vào tính chất luôn hướng về phía cực trị của hàm số , và càng gần với cực trị thì giá trị của càng tiến về không. Vì thế để tìm kiếm cực trị lân cận của một hàm số bất kì, ta chọn một điểm để bắt đầu thuật toán GD và cập nhật giá trị của theo công thức truy hồi sau:
Trong đó, được gọi là tốc độ học của thuật toán.
Đối với gradient decent, người ta thường chọn có độ lớn khoảng đến , tùy vào loại dữ liệu.
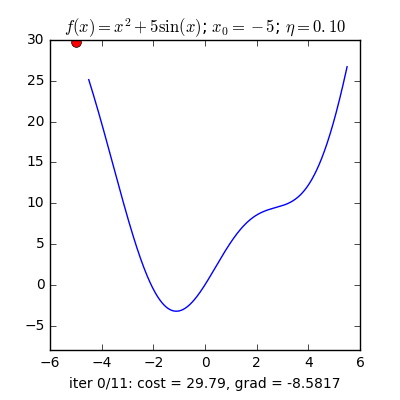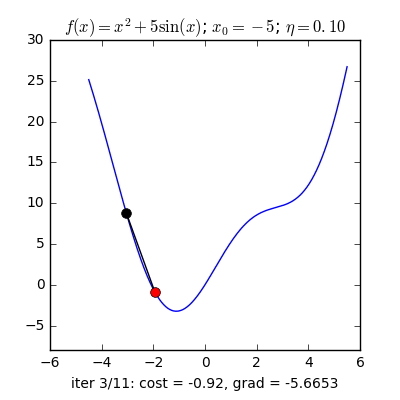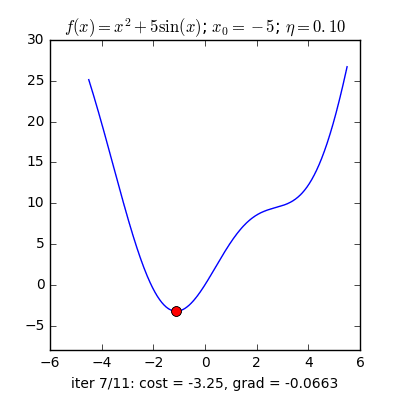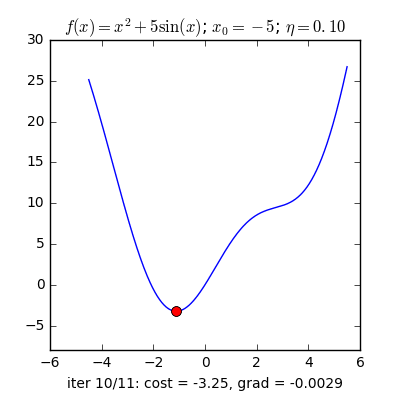
Gradient trong GD thường được tính bằng hai cách, cách đầu tiên là dùng analytical gradient, có được bằng cách áp dụng công thức đạo hàm vào hàm mất mát để tính Gradient, ưu điểm của phương pháp này là khối lượng tính toán nhẹ và độ chính xác cao, nhưng nhược điểm là đôi lúc ta sẽ gặp những bài toán mà hàm mất mát phức tạp đến nỗi không thể tính được công thức đạo hàm. Điều đó dẫn đến cách tính thứ hai đó là numerical Gradient, cách làm này tuy độ chính xác không cao và khối lượng tính toán lớn nhưng bù lại thì nó có thể dùng cho mọi trường hợp hàm mất mát. numerical gradient thường được dùng để kiểm tra analytical gradient để bào đảm ta tính đúng Gradient. Numerical gradient được tính bằng cách sử dụng công thức sai phân hướng tâm:
Gradient decent với momentum
Trong một số trường hợp, thuật toán GD của chúng ta không tìm được một global minimum để thuật toán thu được một kết quả tốt mà lại bị kẹt tại một local minimum, không mong muốn.
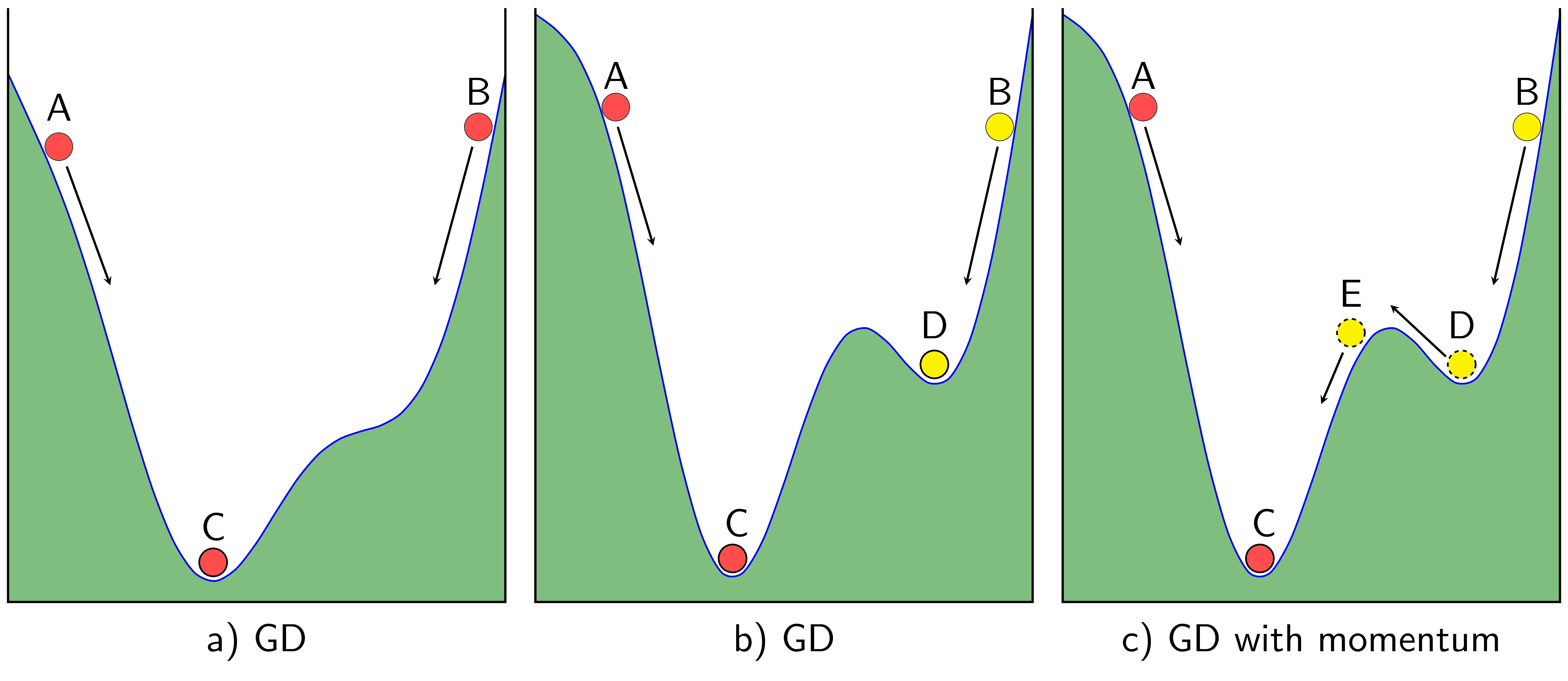
Để khắc phục điểm trừ này, ta thêm vào công thức cập nhật gradient nhân tố có công thức như sau:
Hệ số trong công thức trên thường được đặt là và từ đó công thức GD với momentum có công thức như sau
Trong đó, nhìn theo góc nhìn vật lí thì bao gồm biểu thì cho “đà” của quả banh màu vàng giúp quả banh vàng vượt qua local minimum không mong muốn và thành phần gradient cơ bản , vì thế mà việc thêm “đà” này còn được gọi là rò rỉ động lượng, tức năng lượng ở lần cập nhật trước bị rò rỉ qua lần cập nhật sau với hệ số .
Nesterov accelerated gradient decent (NAG)
Tuy momentum giúp viên bi vàng vượt được dốc để tiến đến cực trị mong muốn nhưng điều này đồng thời cũng khiến nó dao động rất lâu xung quanh điểm cực tiểu trước khi dừng lại. Tuy nhiên, với Nesterov GD thì điều này sẽ được khắc phục. Với hai thuật toán trước, ta chỉ tính Gradient tại điểm đang xét, nhưng với NAG, gradient được tính tại điểm ở “tương lai”:
Thay vì cập nhật với:
NAG cập nhật với:
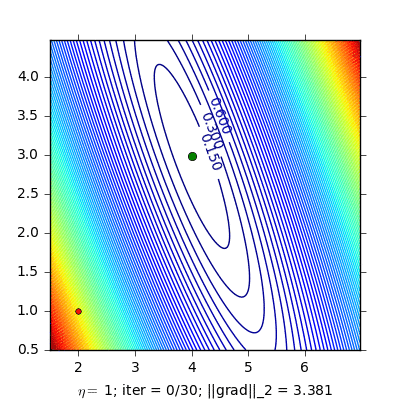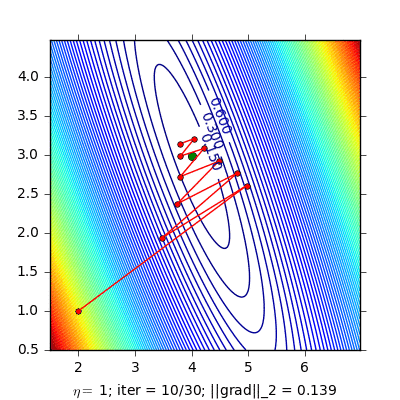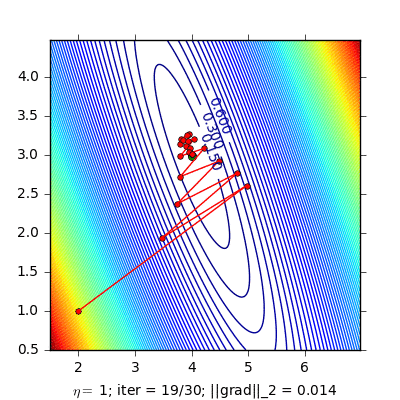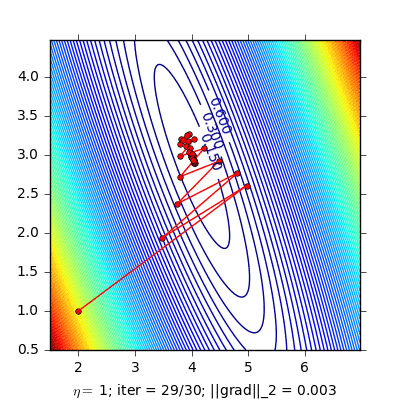
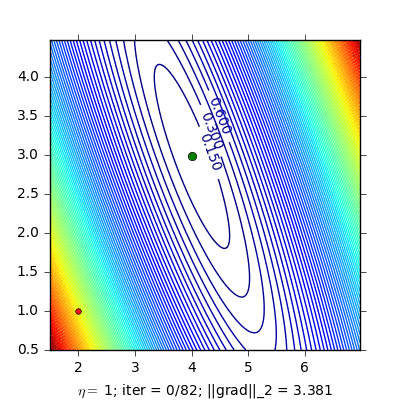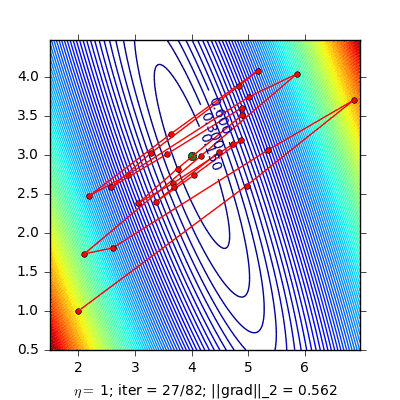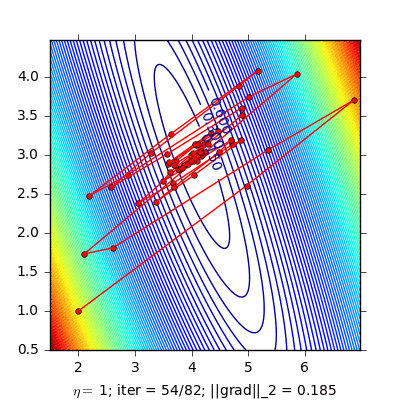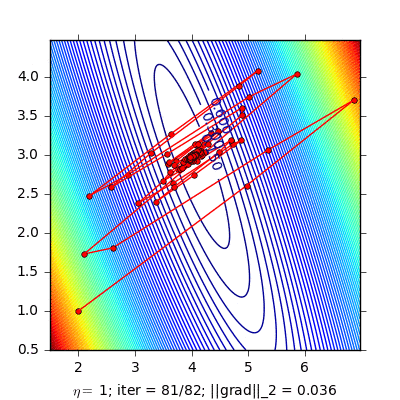
Stochastic gradient decent (SGD)
Cập nhật Gradient chỉ với một điểm dữ liệu ngẫu nhiên và làm điều này trên toàn bộ dữ liệu. Mỗi lần thuật toán đi qua hết tất cả các điểm dữ liệu gọi là một epoch. Để huấn luyện với SGD, ta có thể sẽ phải chạy nhiều epoch.
Ưu điểm của SGD là tốc độ tính toán rất nhanh và không cần nhiều bộ nhớ. Vì thế phương pháp này được ứng dụng rất nhiều trong mảng online learning.
Batch and mini batch
Thay vì dùng một điểm để cập nhật, ta chia nhiều điểm vào chung một batch rồi dùng để cập nhật Gradient. điều này giúp tận dụng dữ liệu và cũng cải thiện tốc độ tính toán. Hàm mất mát của SGD và Batch, mini batch GD không phải bao giờ cũng giảm nhưng nhìn chung là hội tụ càng về cuối. Phương pháp này được sử dụng rộng rãi trong các bài toán Deep learning.
Stopping criteria
Có các chú ý sau khi dừng thuật toán GD:
- Giới hạn số vòng lặp, hay số epoch để hạn chế tình trạng GD không tìm được nghiệm do learning rate quá lớn hoặc tránh tình trạng model của chúng ta bị overfit. Nhược điểm là đôi khi thuật toán GD chưa tìm được nghiệm thì đã bị dừng lại
- So sánh giá trị gradient tại hai lần cập nhật liên tiếp, khi giá trị này đủ nhỏ thì dừng thuật toán. Nhược điểm là đôi khi việc tính gradient như vậy sẽ không có lợi khi dùng SGD hoặc mini batch vì sẽ tốn nhiều bộ nhớ khi có quá nhiều dữ liệu khiến ta không có được lợi thế khi dùng phương pháp này
- So sánh giá trị của hàm mất mát của nghiệm tại hai lần cập nhật liên tiếp, khi nào giá trị này đủ nhỏ thì dừng lại. Nhược điểm của phương pháp này là nếu tại một thời điểm, điểm cập nhật của ta rơi vào vị trí điểm uốn tương đối bằng phẳng thì thuật toán cũng dừng lại trước khi đạt giá trị mong muốn.
- Phương pháp cuối cùng là kiểm tra sau một vài lần cập nhật nhất định. Việc này giúp giảm khối lượng tính toán cũng như giúp thuật toán vượt được những điểm uốn và tím được cực trị phù hợp.
Advance optimization
Một số những trở ngại lớn trong bài toán tối ưu là các local minimum, các điểm uốn (điểm yên ngựa), và vấn đề tiêu biến/ bùng nổ Gradient (Vanishing/ exploding Gradient), ...
AdaGrad
Trong một số trường hợp, việc chọn learning rate phù hợp có thể trở thành một vấn đề nhức nhối. Vấn đề này sẽ được giải quyết với AdaGrad, vì thuật toán này sẽ coi learning rate là một tham số biến thiên sau mỗi lần chạy thuật toán.
AdaGrad thường được dùng trong các vấn đề về sparse feature (đặc trưng thưa), ví dụ như các bài toán về xử lí ngôn ngữ tự nhiên, quảng cáo điện toán, và lọc cộng tác. Thường những những đặc trưng này ít khi được cập nhật để có thể được tối ưu những lại mang những ý nghĩa vô cùng to lớn, còn những đặc trưng có tần số xuất hiện cao thì được cập nhật liên tục. Vì thế, việc có một learning rate cố định hoặc là quá cao đối với những feature được cập nhật nhiều lần hoặc là quá thấp đối với những feature ít được cập nhật.
Công thức của AdaGrad như sau:
Trong đó thường được chọn bằng .


Ta có thể hiểu sự thay đổi learning rate này như một hệ số “ma sát”, “ma sát” này có giá trị lớn ở dốc và có giá trị nhỏ ở vùng bằng phẳng.
Phân tích ưu và nhược của AdaGrad:
Ưu điểm:
- Hoạt động tốt với bài toán sparse feature, cụ thể là tối ưu các bài toán lồi, không dao động nhiều khi đạt vào cực tiểu cần thiết.
- Learning rate được tự động điều chỉnh cho phù hợp
- Chi phí tính toán không tăng nếu so với SGD
Nhược điểm:
- Trong deep learning, các bài toán thường không hoàn toàn lồi và có nhiều local minimum gây nhiễu.
- trong công thức cập nhật tăng một cách dường như tuyến tính khiến cho learning rate bị thu nhỏ nhanh.
RMSProp
AdaGrad với tốc độ học thay đổi để thích nghi với dữ liệu là một phương pháp tuyệt vời trong các bài toán tối ưu lồi, thế nhưng nó vẫn có những hạn chế như đã nêu trên. Vì thế RMSProp được đề xuất để khác phục những vấn đề của AdaGrad bằng cách kế thừa ý tưởng từ phương pháp momentum trong gradient decent làm rò rỉ các giá trị của trong công thức cập nhật. Cụ thể công thức của RMSProp là:
Việc làm cho bị rò rỉ cũng đồng thời chuẩn hóa giá của trị số đứng trước giá trị của , vì thế mà giải quyết được vấn đề learning rate bị thu nhỏ khiến thuật toán dừng sớm.

Ta thấy rằng RMSProp kế thừa được những ưu điểm của AdaGrad về việc tự điều chỉnh learning rate, thuật toán đã đi được xa hơn so với AdaGrad với cùng learning rate
Adam
Trong một bài toán tối ưu thường gặp, ta muốn thuật toán của mình đầu tiên vượt qua những local minimum nhiễu một cách dễ dàng, nhưng khi đạt được global minimum thì sẽ không dao động quá lâu mà tìm được vị trí phù hợp ngay. Điều này thúc đẩy ta tìm kiếm một thuật có hành vi được mô tả như trên.
Có một thuật toán đã hội tụ đủ mọi ưu điểm của những phương pháp trước đó, đó chính là Adam, được sử dụng rất phổ biến trong bài toán deep learning. Thuật toán của Adam được ví như một quả bóng có khối lượng lớn và có ma sát vì nó có động lượng rò rỉ để vượt qua các local minimum để tiến đến gobal ninimum và không dao động lâu vì có ma sát kế thừa từ AdaGrad
Thuật toán của Adam như sau:
Trong đó, và thường được chọn là và . Các giá trị và cũng thường được cho bằng .
Tuy nhiên, Adam tuy có lợi thế về learning rate và động lượng nhưng trong một số trường hợp nhất định, Adam sẽ bắt đầu phân kì. Có một bài báo đã nêu lên và phân tích điều này: [Zaheer et al., 2018]
So sánh các thuật toán tối ưu:
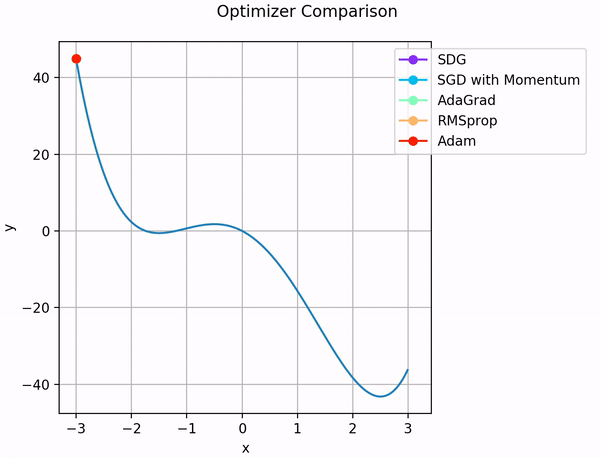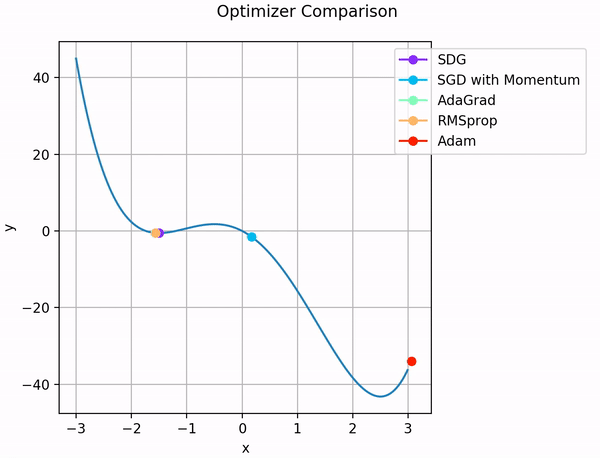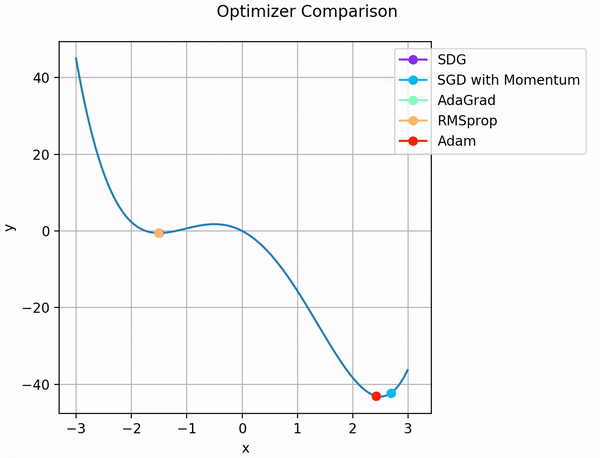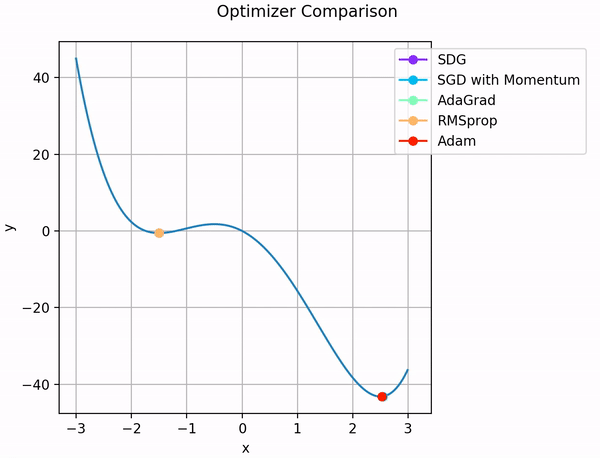

Ngoài ra, ta vẫn có thể sử dụng các thuật toán đơn giản như SGD với momentum, hoặc chỉ SGD nhưng kết hợp với bộ định thời tốc độ học ( Learning rate scheduling) để đạt được tốc độ học mong muốn.
Tài liệu tham khảo
- Sách Machine Learning Cơ bản. Tác giả: bác Vũ Hữu Tiệp
- Sách Dive into deep learning. Nhiều tác giả. link bản tiếng anh. link bản tiếng Việt.
- Ngoài ra mình còn tham khảo một số nguồn ngoài khác nhưng chính thì chỉ có hai nguồn dẫn trên thôi .
All rights reserved
