Hệ điều hành (Phần 2): Tìm hiểu về Multitasking, Scheduler, Shared Memory và CPU Caches
Tiếp nối phần một, sau khi chúng ta đã tìm hiểu về Process và Thread, bài này chúng ta sẽ xem cách mà CPU có thể xử lý hàng nghìn Thread, Process một cách trơn tru với Multitasking và Scheduler, ngoài ra còn các cơ chế cache của CPU giúp nó xử lý siêu nhanh. Bắt đầu thôi 🙃🙃
Nếu thấy hay, kết nối với mình tại LinkedIn.
Hệ điều hành (Phần 1): Tìm hiểu về Process, Thread, Multi-Process và Multi-Thread
Multitasking
Đa nhiệm là khả năng của hệ điều hành trong việc quản lý nhiều tác vụ, như process hoặc thread, cùng một lúc. Ngay cả trên một máy có nhiều core, hệ điều hành vẫn dựa vào đa nhiệm để làm cho nhiều chương trình có cảm giác như đang chạy đồng thời. Trên thực tế, OS chia CPU time thành những lát rất nhỏ và luân phiên giữa các tác vụ rất nhanh, tạo ra ảo giác rằng mọi thứ đang diễn ra cùng lúc.
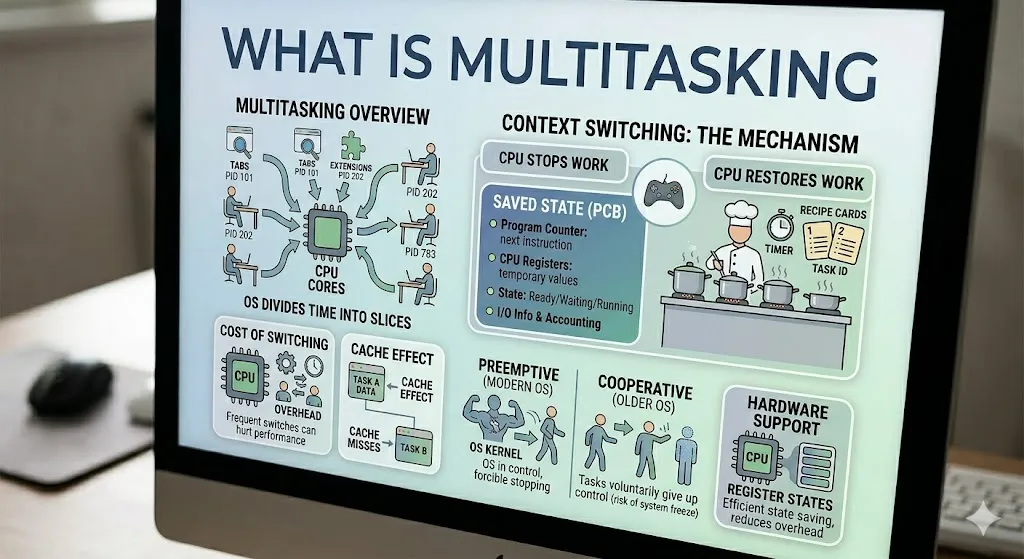
Ở trung tâm của đa nhiệm là Context Switching. Một context switch xảy ra khi CPU dừng chạy một process hoặc thread và chuyển sang process hoặc thread khác. Trước khi chuyển, hệ điều hành phải lưu lại trạng thái thực thi hiện tại, và khi tác vụ đó chạy lại sau này, nó sẽ khôi phục trạng thái đó để tiếp tục đúng vị trí đã dừng.
Bạn có thể tưởng tượng CPU như một đầu bếp đang nấu nhiều món cùng lúc. Trước khi chuyển sang món khác, đầu bếp nhớ lại nhiệt độ, thời gian và trạng thái món ăn. Khi quay lại, đầu bếp xem lại những ghi chú đó và tiếp tục từ đúng chỗ cũ thay vì làm lại từ đầu.
Những gì thường được lưu lại trong một context switch gồm:
- Program Counter: lệnh tiếp theo cần thực thi.
- CPU Registers: các giá trị tạm thời mà CPU đang sử dụng.
- Trạng thái: tác vụ đang ở trạng thái Ready, Running, Waiting hay trạng thái nào khác.
- Thông tin I/O: các thông tin liên quan đến nhập/xuất.
- Thông tin Accounting: các thống kê sử dụng như thời gian CPU đã dùng.
Chi phí của việc chuyển ngữ cảnh
Context switch là cần thiết, nhưng nó không miễn phí. Nó tạo ra overhead, nghĩa là CPU phải dành thời gian cho việc “hậu cần” thay vì làm công việc thực sự. Việc lưu và khôi phục trạng thái tốn thời gian, và nếu xảy ra quá nhiều lần, hiệu năng tổng thể sẽ giảm.
Ngoài ra còn có hiệu ứng cache. Khi CPU chuyển từ tác vụ này sang tác vụ khác, cache có thể vẫn đang chứa dữ liệu của tác vụ trước đó. Tác vụ mới có thể bị cache miss và phải lấy dữ liệu từ main memory chậm hơn, khiến độ trễ tăng thêm. Đây là một lý do khiến quá nhiều context switch có thể làm giảm hiệu năng.
Preemptive và Cooperative
Các hệ điều hành hiện đại thường dùng preemptive multitasking. Trong mô hình này, OS là bên chủ động và có thể buộc một tác vụ dừng lại khi hết time slice. Điều này giúp hệ thống phản hồi tốt và ngăn một tác vụ chiếm toàn bộ CPU.
Các hệ thống cũ đôi khi dùng cooperative multitasking. Trong mô hình này, các tác vụ phải tự nguyện nhường quyền điều khiển. Nếu một tác vụ bị treo hoặc hoạt động sai, cả hệ thống có thể trở nên không phản hồi. Đó là lý do preemptive multitasking trở thành chuẩn trong các hệ điều hành hiện đại.
Hỗ trợ từ phần cứng
Các CPU hiện đại cũng có những cơ chế phần cứng giúp context switching diễn ra hiệu quả hơn. CPU có thể lưu và khôi phục trạng thái thanh ghi rất nhanh, giúp giảm một phần chi phí chuyển đổi. Tuy vậy, context switching vẫn có chi phí hiệu năng thật sự, đặc biệt khi nó xảy ra quá thường xuyên.
Tóm lại, multitasking là bức tranh tổng thể, còn context switching là cơ chế bên trong giúp nó hoạt động. Multitasking cho phép nhiều tác vụ chia sẻ một CPU theo thời gian, còn context switching là quá trình thực sự chuyển từ tác vụ này sang tác vụ khác rồi quay lại.
Scheduler
Scheduler là một thành phần cốt lõi của nhân hệ điều hành, có nhiệm vụ quyết định process hoặc thread nào được chạy trên CPU tại một thời điểm nhất định. Nói đơn giản, nó giống như đạo diễn của một sân khấu: quyết định ai lên sân khấu trước, ai phải chờ, và mỗi người được biểu diễn trong bao lâu.
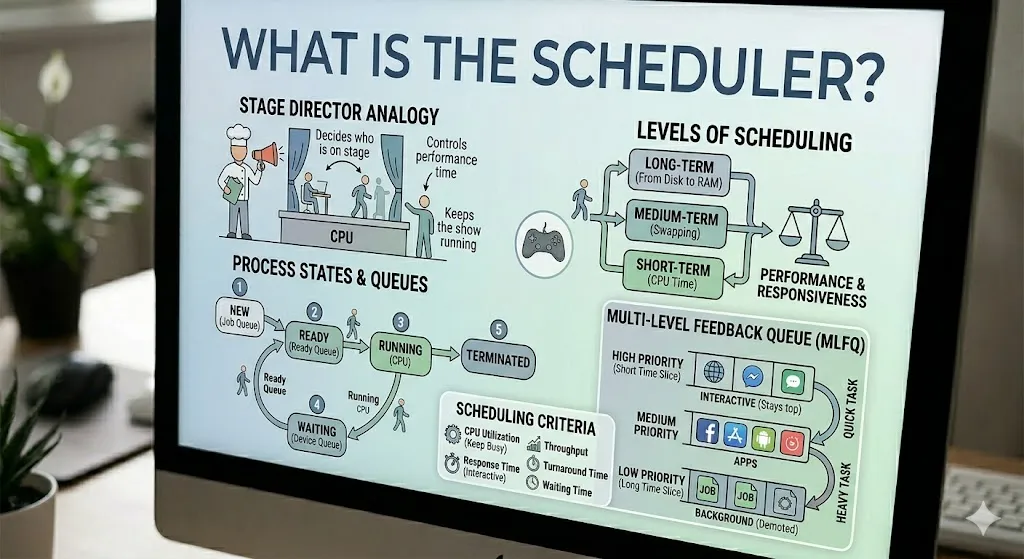
Scheduler không chỉ quyết định cái gì được chạy, mà còn quyết định chạy trong bao lâu. Khi time slice của một tác vụ kết thúc, hoặc khi nó phải chờ I/O, scheduler sẽ chuyển CPU sang tác vụ khác để hệ thống vẫn phản hồi tốt và không lãng phí thời gian CPU.
Ba mức độ lập lịch
Trong các hệ điều hành hiện đại, lập lịch thường được chia thành ba mức:
- Long-term scheduler: quyết định job nào được nhận vào hệ thống từ đĩa vào bộ nhớ. Nó kiểm soát mức độ đa chương trình.
- Short-term scheduler: còn gọi là CPU scheduler, đây là phần chọn tác vụ từ Ready Queue và cấp CPU cho nó. Nó chạy rất thường xuyên và phải cực kỳ nhanh.
- Medium-term scheduler: xử lý swapping. Khi bộ nhớ bị áp lực, nó có thể tạm thời đẩy một process ra khỏi RAM rồi đưa nó quay lại sau.
Ba vai trò này phối hợp với nhau để cân bằng giữa hiệu năng, sử dụng bộ nhớ và khả năng phản hồi.
Trạng thái process và các hàng đợi
Một process thường đi qua một số trạng thái:
- New: process đang được tạo.
- Ready: process đã sẵn sàng chạy và đang chờ trong Ready Queue.
- Running: process đang sử dụng một CPU core.
- Waiting hoặc Blocked: process không thể chạy vì đang chờ một sự kiện chậm, như I/O đĩa hoặc thao tác từ người dùng.
- Terminated: process đã hoàn tất và đang được dọn dẹp tài nguyên.
Một điểm dễ nhầm là process thường không đi thẳng từ Waiting sang Running. Nó phải quay lại Ready Queue trước, rồi chờ short-term scheduler chọn lại.
Các hàng đợi trong lập lịch
Hệ điều hành dùng nhiều hàng đợi khác nhau để tổ chức process và thread:
- Job Queue: chứa các job chưa được đưa vào bộ nhớ.
- Ready Queue: chứa các process hoặc thread đã sẵn sàng chạy trên CPU.
- Device Queue: chứa các process hoặc thread đang chờ thiết bị I/O như đĩa, mạng, hoặc các thiết bị ngoại vi khác.
Khi một process thay đổi trạng thái, nó sẽ chuyển sang hàng đợi phù hợp. Ví dụ, nếu một process đang chạy mà cần đọc dữ liệu từ đĩa, nó sẽ rời CPU và chuyển sang Device Queue. Khi I/O hoàn tất, nó quay lại Ready Queue và chờ CPU lần nữa.
Tiêu chí lập lịch
Khi chọn một thuật toán lập lịch, hệ điều hành thường cân bằng giữa nhiều mục tiêu:
- CPU utilization: giữ CPU bận nhiều nhất có thể.
- Throughput: hoàn thành càng nhiều job càng tốt trong một khoảng thời gian nhất định.
- Turnaround time: giảm thời gian từ New đến Terminated.
- Response time: giảm độ trễ giữa hành động của người dùng và phản hồi đầu tiên nhìn thấy.
- Fairness: đảm bảo không có tác vụ nào bị đói CPU quá lâu.
- Waiting time: giảm thời gian tác vụ phải chờ trước khi được cấp CPU.
Lựa chọn tốt nhất phụ thuộc vào mục tiêu của hệ thống. Một máy chủ có thể ưu tiên throughput và CPU utilization, trong khi một hệ điều hành máy tính để bàn lại quan tâm nhiều hơn đến response time và fairness.
Các thuật toán lập lịch
Một số thuật toán lập lịch thường gặp:
- First Come, First Serve (FCFS): tác vụ nào đến trước thì chạy trước.
- Round Robin (RR): mỗi tác vụ được cấp một time slice cố định, rồi CPU chuyển sang tác vụ tiếp theo.
- Priority Scheduling: tác vụ có ưu tiên cao hơn được chạy trước.
- Shortest Job First (SJF): tác vụ có khối lượng công việc nhỏ hơn được ưu tiên.
- Shortest Remaining Time: tác vụ còn ít thời gian xử lý nhất sẽ được chọn.
- Multi-level Queue: hệ thống được chia thành nhiều hàng đợi, mỗi hàng đợi có chính sách lập lịch riêng.
Mỗi thuật toán đều có sự đánh đổi giữa khả năng phản hồi, tính công bằng và hiệu quả. Round Robin đơn giản và công bằng, nhưng có thể tạo ra nhiều context switch hơn. SJF có thể giảm thời gian chờ trung bình, nhưng khó dùng trong thực tế vì hệ điều hành phải ước lượng thời lượng của job.
Multi-level Feedback Queue
Hầu hết các hệ điều hành hiện đại không chỉ dựa vào một mô hình lập lịch đơn giản. Một cách tiếp cận thực tế rất phổ biến là Multi-level Feedback Queue (MLFQ).
Trong MLFQ, một tác vụ mới thường bắt đầu ở hàng đợi ưu tiên cao với time slice ngắn. Nếu nó hoạt động như một tác vụ tương tác nhanh, nó sẽ ở gần mức cao. Nếu nó tiếp tục dùng quá nhiều CPU, hệ điều hành sẽ dần đẩy nó xuống các hàng đợi ưu tiên thấp hơn với time slice dài hơn. Điều này giúp giao diện người dùng vẫn mượt mà, đồng thời các job lớn vẫn có thể hoàn thành.
CPU-bound và I/O-bound
Các loại workload khác nhau cần cách lập lịch khác nhau:
- CPU-bound tasks: dành phần lớn thời gian để tính toán.
- I/O-bound tasks: dành phần lớn thời gian để chờ đĩa, mạng hoặc thiết bị khác.
Scheduler thường cố gắng ưu tiên các tác vụ ngắn hoặc tương tác nhanh để hệ thống có cảm giác phản hồi tốt, đồng thời vẫn đảm bảo các tác vụ CPU-bound cuối cùng cũng được xử lý đủ thời gian.
Shared Memory
Shared Memory là một trong những phương pháp nhanh nhất để giao tiếp giữa các process (Inter-Process Communication - IPC). Thay vì gửi dữ liệu qua lại thông qua kernel, hệ điều hành sẽ ánh xạ cùng một vùng nhớ vật lý vào không gian địa chỉ ảo của nhiều process. Điều đó có nghĩa là cùng một dữ liệu có thể được truy cập trực tiếp bởi nhiều process.
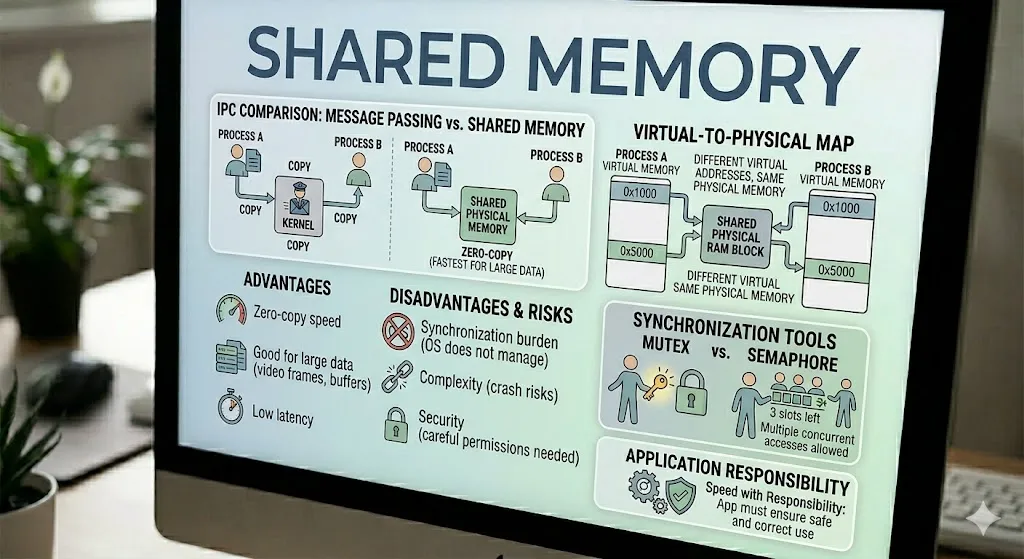
Shared Memory và Message Passing
Có hai cách chính để các process giao tiếp với nhau:
- Message passing: OS đóng vai trò như người đưa thư. Process A gửi dữ liệu vào kernel, rồi kernel chuyển dữ liệu đó cho Process B. Cách này an toàn hơn, nhưng thường phải copy dữ liệu nhiều hơn một lần.
- Shared memory: OS cung cấp một vùng nhớ chung để cả hai process có thể đọc và ghi trực tiếp. Cách này tránh được việc copy dữ liệu và nhanh hơn nhiều, đặc biệt với dữ liệu lớn.
Đó là lý do vì sao shared memory thường là lựa chọn ưu tiên khi tốc độ là yếu tố quan trọng nhất.
Nó hoạt động như thế nào ?
Hệ điều hành lấy một khối RAM vật lý và ánh xạ nó vào không gian địa chỉ ảo của hai hoặc nhiều process.
Ví dụ:
- Với Process A, dữ liệu chia sẻ có thể xuất hiện ở địa chỉ
0x1000. - Với Process B, cùng vùng nhớ vật lý đó có thể xuất hiện ở địa chỉ
0x5000.
Dù địa chỉ ảo khác nhau, cả hai process đều đang nhìn vào cùng một vùng nhớ vật lý bên dưới.
Ưu điểm
- Giao tiếp không cần copy (zero-copy): sau khi bộ nhớ đã được ánh xạ, dữ liệu di chuyển với tốc độ của bộ nhớ thay vì phải đi qua kernel.
- Tốt cho dữ liệu lớn: shared memory rất phù hợp cho video frames, database buffers, và các tập dữ liệu lớn khác.
- Độ trễ thấp: thường nhanh hơn pipes hoặc sockets khi cần trao đổi dữ liệu thường xuyên.
Nhược điểm và rủi ro
- Gánh nặng đồng bộ: OS không tự động quản lý truy cập, nên chúng ta phải tự bảo vệ dữ liệu dùng chung bằng atomic operations, mutex, semaphore hoặc lock.
- Độ phức tạp: nếu một process bị crash trong lúc đang giữ lock, các process khác có thể bị kẹt, hoặc dữ liệu chia sẻ có thể bị hỏng.
- Bảo mật: nếu phân quyền không được cấu hình cẩn thận, shared memory có thể trở thành rủi ro cho việc truy cập dữ liệu trái phép.
Mutex và Semaphore
Nên phân biệt rõ các công cụ đồng bộ phổ biến:
- Mutex: giống như một chiếc chìa khóa vào nhà vệ sinh. Chỉ một thread hoặc process có thể giữ nó tại một thời điểm.
- Semaphore: giống như bộ đếm của một bãi đỗ xe. Nó cho phép một số lượng giới hạn thread hoặc process truy cập tài nguyên cùng lúc.
Shared memory rất mạnh vì nó mang lại tốc độ, nhưng đổi lại là trách nhiệm. Hệ điều hành chỉ cung cấp vùng nhớ chung, còn ứng dụng phải đảm bảo nó được sử dụng an toàn và đúng cách.
CPU Caches
Các CPU hiện đại sử dụng một cache hierarchy để bù đắp khoảng cách tốc độ rất lớn giữa CPU và bộ nhớ chính (DRAM). Cấp độ nhớ càng gần core CPU thì càng nhanh, nhưng cũng càng nhỏ.

Thông thường, CPU có ba mức cache chính:
- L1: cache nhỏ nhất và nhanh nhất. Nó thường được chia thành:
- L1i cho instruction.
- L1d cho data.
- L2: lớn hơn L1 nhưng chậm hơn một chút. Trong nhiều thiết kế hiện đại, nó đóng vai trò như bộ đệm cho L1 và có thể được chia sẻ bởi một cụm core nhỏ.
- L3: còn gọi là Last Level Cache (LLC). Nó lớn hơn nhiều, thường tính bằng MB, và có thể được chia sẻ giữa nhiều core.
![image.png]()
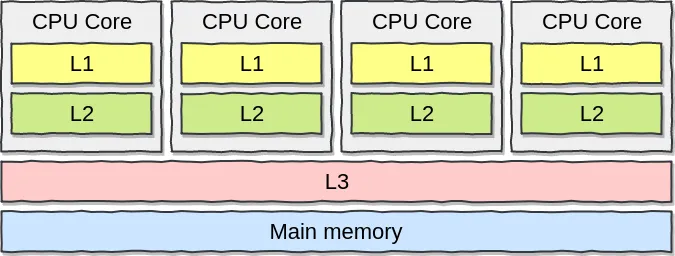
Khi CPU cần dữ liệu, nó sẽ kiểm tra L1 trước, rồi đến L2, L3, và cuối cùng là DRAM nếu không tìm thấy dữ liệu trong cache. Thiết kế nhiều tầng này giúp giữ dữ liệu hay dùng ở gần bộ xử lý hơn, từ đó giảm đáng kể thời gian truy cập bộ nhớ trung bình.
Cache Line: Đơn vị truyền dữ liệu
Dữ liệu được chuyển giữa các mức nhớ theo từng khối cố định gọi là cache line. Trên nhiều CPU hiện đại, một cache line thường là 64 byte.
CPU không lấy từng byte hay từng số nguyên riêng lẻ. Thay vào đó, nó tải cả một cache line vì nó dự đoán rằng dữ liệu lân cận cũng sẽ sớm được dùng đến. Đó là lý do cache line rất quan trọng trong chương trình thực tế.
Nguyên lý Locality
Cơ chế này dựa trên spatial locality. Nếu CPU truy cập một giá trị trong bộ nhớ, nó thường giả định rằng các giá trị ở gần đó cũng sẽ sớm được truy cập.
Đó là lý do vì sao mảng thường thân thiện với cache. Các phần tử của mảng nằm cạnh nhau trong bộ nhớ, nên CPU có thể tận dụng cache line hiệu quả. Ngược lại, linked list thường rải các node khắp bộ nhớ, khiến việc sử dụng cache kém hiệu quả hơn nhiều.
Cache Hit và Cache Miss
Khi CPU tìm dữ liệu, sẽ có hai trường hợp:
- Cache hit: dữ liệu được tìm thấy trong cache, nên chương trình tiếp tục rất nhanh.
- Cache miss: dữ liệu không có trong cache, nên CPU phải lấy từ mức thấp hơn, thường là cache chậm hơn hoặc DRAM.
Cache miss rất tốn kém. CPU có thể phải chờ hàng chục hoặc thậm chí hàng trăm chu kỳ trong lúc dữ liệu được nạp vào. Đó là lý do vì sao cache tốt có thể ảnh hưởng rất lớn đến hiệu năng.
Set-Associativity và Tag
Cache không được quản lý như một hash table đơn giản. Thay vào đó, nó dùng cấu trúc set-associative.
CPU sử dụng một số bit nhất định của địa chỉ bộ nhớ để chọn một set trong cache, sau đó so sánh tag để kiểm tra xem dữ liệu có thực sự nằm ở đó hay không. Thiết kế này giúp phần cứng tìm dữ liệu rất nhanh mà không cần quét toàn bộ cache.
Mỗi cache line thường chứa:
- Dữ liệu thực tế.
- Một tag để xác định block bộ nhớ mà nó thuộc về.
- Metadata như trạng thái hợp lệ và trạng thái dirty.
Write-Back và Dirty Cache Line
Để giữ tốc độ cao, CPU thường dùng chính sách write-back. Khi dữ liệu bị sửa, thay đổi sẽ được ghi vào cache trước, và cache line sẽ được đánh dấu là "dirty".
Bộ nhớ chính không được cập nhật ngay lập tức. Thay vào đó, dữ liệu sẽ được ghi xuống sau, thường là khi:
- cache line bị thay ra, hoặc
- việc đồng bộ bị ép buộc bởi memory barrier,
volatile, hoặcatomic operations.
Cách này giúp giảm lưu lượng truy cập đến DRAM và tăng hiệu năng, nhưng cũng có nghĩa là cache và bộ nhớ có thể tạm thời chứa hai phiên bản khác nhau của cùng một dữ liệu.
Cache Coherency
Trên CPU nhiều core, mỗi core có thể có cache riêng. Điều đó tạo ra một vấn đề: nếu Core 1 sửa dữ liệu trong cache của nó, làm sao Core 2 biết bản sao của nó đã cũ?
Để giải quyết, CPU sử dụng các cache coherency protocol như MESI. Các giao thức này giúp các core phối hợp với nhau để không tiếp tục dùng giá trị cũ. Trong thực tế, điều này đảm bảo rằng mọi core cuối cùng đều thấy phiên bản mới nhất của dữ liệu dùng chung.
False Sharing
Một vấn đề hiệu năng rất khó nhận ra gọi là false sharing có thể xảy ra khi hai thread cập nhật hai biến khác nhau, nhưng hai biến đó lại nằm trên cùng một cache line.
Dù về mặt logic các biến là độc lập, phần cứng vẫn coi cả cache line là một đơn vị chia sẻ. Kết quả là cache line cứ bị đẩy qua lại giữa các core, và hiệu năng giảm mạnh.
False sharing đặc biệt nguy hiểm vì code có thể trông hoàn toàn đúng và không có tranh chấp rõ ràng, nhưng vẫn chạy chậm do cách sắp xếp cache line.
Vì sao Cache quan trọng
Cache là một trong những lý do lớn nhất khiến CPU hiện đại nhanh như vậy. Nó giảm chi phí trung bình của việc truy cập bộ nhớ, giúp CPU luôn có việc để làm, và làm cho việc truy cập dữ liệu lặp lại hoặc dữ liệu gần nhau trở nên rẻ hơn nhiều.
Nhưng cache cũng tạo ra sự phức tạp. Để viết code hiệu năng cao, bạn không chỉ cần nghĩ về thuật toán, mà còn phải nghĩ đến pattern truy cập bộ nhớ, cache locality, cache coherency và false sharing.
Kết
Khi hiểu process, thread, scheduler và cache, bạn sẽ thấy rõ hơn vì sao một số đoạn code chạy nhanh, một số đoạn lại chậm, vì sao có lỗi đồng bộ, và vì sao AI không thể thay thế hoàn toàn tư duy hệ thống. Kiến thức nền tảng không làm bạn viết code thay AI, nhưng nó giúp bạn biết nên hỏi AI cái gì, và kiểm tra kết quả của AI ra sao.
Bài viết này cũng được mình dịch sang tiếng Anh trên blog substack của mình.
Mình viết lại những điều này như một cách để ghi nhớ hành trình làm nghề của mình. Nếu bạn cũng đang làm backend, devops hoặc cloud, hy vọng những chia sẻ này có thể giúp bạn một chút gì đó. Còn nếu có chỗ nào mình hiểu chưa đúng, mình vẫn luôn sẵn sàng học thêm.
All rights reserved
