Giám sát hệ thống Kubernetes hiệu quả với Prometheus Stack và Helm
Bạn đang tìm kiếm giải pháp giám sát toàn diện cho cụm Kubernetes của mình? Bài viết này sẽ hướng dẫn bạn cách triển khai Prometheus Stack bằng Helm, cung cấp khả năng giám sát ứng dụng và hạ tầng mạnh mẽ.
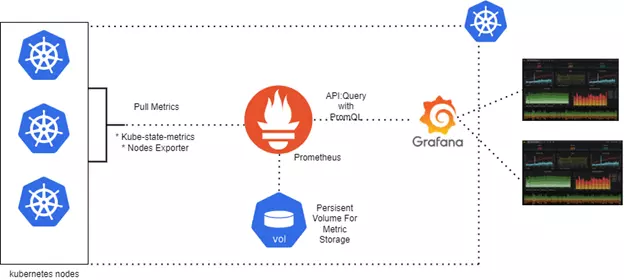
Chúng ta có thể cài đặt toàn bộ Prometheus Stack vào cụm Kubernetes bằng cách sử dụng biểu đồ Helm từ Cộng đồng Prometheus. Bạn sẽ triển khai một bộ công cụ được gọi chung là kube-prometheus-stack. Stack này bao gồm Prometheus, Alertmanager, Grafana và các thành phần giám sát và cảnh báo khác được thiết kế riêng cho môi trường Kubernetes.
Dưới đây là tổng quan về các thành phần chính sẽ được cài đặt và cách sử dụng chúng để giám sát ứng dụng và cụm:
1. Prometheus: Trái tim của hệ thống giám sát
Mục đích: Prometheus là công cụ giám sát và cảnh báo cốt lõi. Nó thu thập và lưu trữ số liệu, cung cấp ngôn ngữ truy vấn (PromQL) để phân tích số liệu và kích hoạt cảnh báo dựa trên các ngưỡng đã xác định.
Cách sử dụng Prometheus để giám sát:
- Thu thập số liệu: Prometheus thu thập số liệu từ nhiều nguồn khác nhau như các nút Kubernetes, pod và dịch vụ.
- Cảnh báo: Prometheus hỗ trợ xác định các quy tắc cảnh báo, được sử dụng để kích hoạt cảnh báo dựa trên ngưỡng số liệu (ví dụ: sử dụng CPU cao).
- Lưu trữ dài hạn: Prometheus lưu trữ dữ liệu chuỗi thời gian để phân tích và giám sát, mặc dù nó thường bị giới hạn trong việc lưu giữ ngắn hạn hoặc trung hạn.
2. Alertmanager: Quản lý cảnh báo thông minh
Mục đích: Alertmanager nhận cảnh báo từ Prometheus và xử lý việc loại bỏ trùng lặp, nhóm và định tuyến cảnh báo đến các kênh thông báo khác nhau (ví dụ: Slack, email, PagerDuty).
Cách sử dụng Alertmanager để quản lý cảnh báo:
- Quản lý cảnh báo: Đảm bảo rằng chỉ các cảnh báo có thể hành động được gửi đến các nhóm trực, giảm thiểu nhiễu.
- Định tuyến thông báo: Các tuyến có thể định cấu hình cho phép cảnh báo được chuyển đến đúng nhóm hoặc người.
- Tắt tiếng: Tạm thời tắt tiếng cảnh báo trong quá trình bảo trì hoặc sự cố đã biết để tránh thông báo không cần thiết.
3. Grafana: Biến dữ liệu thành thông tin
Mục đích: Grafana là một công cụ trực quan hóa dữ liệu tích hợp với Prometheus để tạo bảng điều khiển tùy chỉnh, cung cấp thông tin chi tiết theo thời gian thực về các số liệu ứng dụng và cơ sở hạ tầng.
Cách sử dụng Grafana:
- Trực quan hóa: Tạo bảng điều khiển tương tác để trực quan hóa các số liệu được thu thập bởi Prometheus, cho phép giám sát các ứng dụng, cụm và hơn thế nữa.
- Cảnh báo: Grafana cũng có thể thiết lập cảnh báo dựa trên các truy vấn bảng điều khiển, bổ sung cho cảnh báo Prometheus.
- Bảng điều khiển cộng đồng: Cộng đồng Grafana cung cấp một loạt các bảng điều khiển được xây dựng sẵn cho Kubernetes, Prometheus và các ứng dụng khác nhau.
4. kube-state-metrics: Theo dõi trạng thái Kubernetes
Mục đích: kube-state-metrics tạo ra các số liệu về trạng thái của các đối tượng Kubernetes (ví dụ: Triển khai, Pod, Nút) bằng cách truy vấn máy chủ API Kubernetes.
Cách sử dụng để giám sát:
- Giám sát đối tượng Kubernetes: Cung cấp các số liệu chi tiết về tình trạng và trạng thái của tài nguyên Kubernetes, chẳng hạn như số lượng bản sao có sẵn trong Triển khai hoặc trạng thái của Pod.
- Bổ sung cho Node Exporter: Trong khi Node Exporter tập trung vào các số liệu cấp nút, kube-state-metrics cung cấp thông tin chi tiết về tình trạng và tình trạng tài nguyên cụ thể của Kubernetes.
5. Node Exporter: Giám sát sức khỏe nút
Mục đích: Node Exporter thu thập các số liệu cấp hệ thống từ mỗi nút Kubernetes, bao gồm các số liệu CPU, bộ nhớ, đĩa và mạng.
Cách sử dụng Node Exporter để giám sát:
- Giám sát cấp hệ thống: Đảm bảo rằng tình trạng của nút và việc sử dụng tài nguyên được theo dõi, giúp phát hiện các sự cố về phần cứng hoặc tài nguyên.
- Số liệu cấp náy chủ: Cung cấp các số liệu không dành riêng cho Kubernetes nhưng rất quan trọng đối với tình trạng của cơ sở hạ tầng (ví dụ: dung lượng đĩa, độ trễ mạng).
6. Prometheus Operator: Tự động quản lý Prometheus
Mục đích: Prometheus Operator đơn giản hóa việc triển khai và quản lý Prometheus, Alertmanager và các thành phần liên quan bằng cách sử dụng các tài nguyên tùy chỉnh của Kubernetes.
Cách sử dụng để giám sát:
- Quản lý Prometheus tự động: Tự động hóa các tác vụ như mở rộng quy mô, cấu hình và triển khai các phiên bản Prometheus.
- Tài nguyên tùy chỉnh để cấu hình: Cung cấp các tài nguyên tùy chỉnh như ServiceMonitor, PodMonitor, PrometheusRule và Alertmanager để cấu hình và quản lý các thành phần giám sát ngay trong Kubernetes.
7. ServiceMonitor và PodMonitor: Định cấu hình thu thập số liệu linh hoạt
Mục đích: Các tài nguyên tùy chỉnh ServiceMonitor và PodMonitor được sử dụng để định cấu hình Prometheus để thu thập số liệu từ các dịch vụ và pod Kubernetes cụ thể, tương ứng.
Cách sử dụng để giám sát:
- Khám phá dịch vụ và Pod: Cho phép Prometheus tự động khám phá và thu thập số liệu từ các ứng dụng, dựa trên nhãn và bộ chọn được xác định trong ServiceMonitor hoặc PodMonitor.
- Cấu hình thu thập chi tiết: Cho phép kiểm soát chi tiết các điểm cuối mà Prometheus nên giám sát, bao gồm khoảng thời gian thu thập và đường dẫn.
8. PrometheusRule: Xây dựng quy tắc cảnh báo và ghi
Mục đích: Xác định các quy tắc cảnh báo và ghi mà Prometheus sử dụng để tạo cảnh báo và tổng hợp số liệu.
Cách sử dụng để giám sát:
- Cấu hình cảnh báo: Chỉ định các điều kiện mà cảnh báo nên được tạo (ví dụ: sử dụng bộ nhớ cao, pod bị lỗi).
- Tổng hợp số liệu: Sử dụng các quy tắc ghi để tính toán trước các truy vấn số liệu phổ biến để truy cập nhanh hơn và sử dụng tài nguyên hiệu quả hơn.
Các bước cài đặt sử dụng Helm
Để cài đặt kube-prometheus-stack thông qua Helm:
1. Thêm kho lưu trữ Helm từ cộng đồng Prometheus:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
2. Cài đặt biểu đồ Helm kube-prometheus-stack:
helm install prometheus-stack prometheus-community/kube-prometheus-stack --namespace monitoring --create-namespace
3. Xác minh cài đặt:
kubectl get pods -n monitoring
Bạn sẽ thấy các pod cho Prometheus, Alertmanager, Grafana, kube-state-metrics, Node Exporter và các thành phần khác.
4. Truy cập Grafana:
kubectl port-forward svc/prometheus-stack-grafana 3000:80 -n monitoring
Truy cập Grafana tại http://localhost:3000 và đăng nhập bằng thông tin đăng nhập mặc định (thường là admin/admin).
Tóm tắt lại quy trình giám sát
- Thu thập số liệu: Prometheus thu thập dữ liệu từ cụm bằng cách sử dụng Node Exporter, kube-state-metrics và ServiceMonitors hoặc PodMonitors tùy chỉnh cho các số liệu cụ thể của ứng dụng.
- Trực quan hóa: Grafana trực quan hóa dữ liệu này, cung cấp thông tin chi tiết theo thời gian thực về hiệu suất của ứng dụng và cụm.
- Cảnh báo: Prometheus tạo cảnh báo dựa trên cấu hình PrometheusRule, sau đó được định tuyến bởi Alertmanager để quản lý thông báo.
Thiết lập này cung cấp một giải pháp giám sát toàn diện bao gồm cả số liệu cụ thể của Kubernetes và cấp máy chủ, giúp đảm bảo rằng các ứng dụng và cơ sở hạ tầng của bạn được giám sát và đáng tin cậy một cách nhất quán.
Cảm ơn các bạn đã theo dõi.
All Rights Reserved
