Giải phẫu Apache Kafka: Những mảnh ghép làm nên cỗ máy lưu trữ siêu tốc

Mỗi khi bạn mở ứng dụng đặt một cuốc xe, lướt xem một gợi ý mua sắm, hay quẹt một chiếc thẻ tín dụng, thứ bạn thấy chỉ là một giao diện mượt mà và tĩnh lặng. Nhưng ẩn dưới bề mặt hoàn hảo ấy là một thế giới ngầm hỗn loạn — nơi hàng triệu điểm dữ liệu đang va đập vào nhau trong từng tích tắc.
Hãy thử tưởng tượng bạn là người kiến trúc sư đứng trong bóng tối, nắm giữ sinh mệnh của thế giới đó. Bạn phải hứng trọn cơn mưa tọa độ GPS từ hàng triệu chiếc xe đang lao đi trên phố, tính toán sự tăng vọt của giá cước ngay khi một giọt mưa vừa chạm đất, và chốt hạ những giao dịch tiền tỷ mà không được phép đánh rơi dù chỉ một đồng.
Nếu giao phó trọng trách này cho những hệ cơ sở dữ liệu truyền thống, chúng sẽ lập tức vỡ vụn và tắt thở trước áp lực khổng lồ.
Nhưng thế giới số của chúng ta không hề sụp đổ. Tại sao?
Bởi vì sâu thẳm trong các trung tâm dữ liệu của những gã khổng lồ công nghệ, có một cỗ máy phi thường đang âm thầm nhịp đập: Apache Kafka. Vượt xa khỏi định nghĩa của một trạm trung chuyển tin nhắn, Kafka đã vươn mình trở thành "hệ thần kinh trung ương", thao túng toàn bộ luồng sự kiện thời gian thực của thế giới hiện đại.
Bằng thứ ma thuật kiến trúc nào mà cỗ máy này có thể nuốt trọn hàng triệu sự kiện mỗi giây với tốc độ ánh sáng, nhưng vẫn đưa ra lời thề độc không bao giờ làm bốc hơi dữ liệu của bạn?
Đã đến lúc bước qua cánh cửa phòng máy chủ. Hãy cùng cầm dao lên và bắt đầu "giải phẫu" từng mảnh ghép cấu tạo nên trái tim của cỗ máy bất tử này.
Phần 1: Khám phá "động cơ" siêu tốc ⚡
Sức mạnh vô đối của Kafka không đến từ những thuật toán ma thuật trên mây, mà bắt nguồn từ cách nó thấu hiểu và bóc lột triệt để giới hạn vật lý của phần cứng máy chủ. Cụ thể, Kafka sở hữu hai thứ vũ khí bí mật:
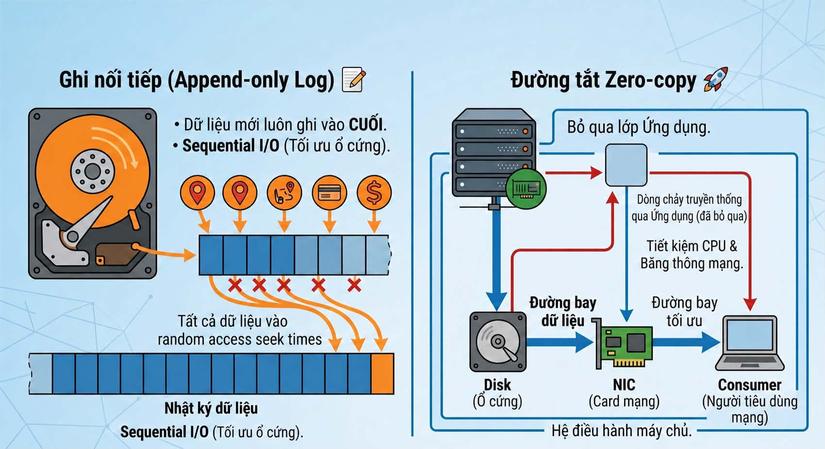
1. Nhật ký ghi nối tiếp (Append-only Log) 📝
Nhiều người mặc định rằng ổ cứng (disk) thì chậm, còn RAM thì nhanh. Tuy nhiên, Kafka lại nổi tiếng với việc lưu trữ dữ liệu bền bỉ xuống ổ cứng mà vẫn đạt tốc độ xử lý hàng triệu tin nhắn mỗi giây. Bí quyết đầu tiên nằm ở cách nó tổ chức ghi dữ liệu.
Thay vì sử dụng các cấu trúc dữ liệu phức tạp như cây B-Tree (thường thấy trong các cơ sở dữ liệu như MySQL hay PostgreSQL) vốn yêu cầu các thao tác đọc/ghi ngẫu nhiên (random I/O), Kafka sử dụng một cấu trúc cực kỳ đơn giản: Append-only log (Nhật ký chỉ ghi thêm).
Hãy tưởng tượng nó giống như một cuốn sổ nhật ký 📖. Khi có tin nhắn mới tới, Kafka chỉ đơn giản là chèn tiếp dữ liệu vào ngay vị trí cuối cùng của tệp. Thao tác ghi tuần tự (sequential write) này trên ổ cứng thực sự rất nhanh, đôi khi có thể ngang ngửa tốc độ ghi ngẫu nhiên trên RAM.
Thêm vào đó, Kafka tận dụng tối đa bộ nhớ đệm của hệ điều hành thông qua OS Page Cache ⚡. Khi có dữ liệu mới, Kafka ghi thẳng vào Page Cache (vùng nhớ trên RAM do hệ điều hành quản lý) chứ không ép hệ thống phải ghi ngay lập tức xuống đĩa cứng vật lý. Việc xả (flush) dữ liệu từ RAM xuống đĩa cứng sẽ do hệ điều hành tự động gom nhóm và lo liệu ở phía sau một cách tối ưu nhất.
Tuy nhiên nếu cứ ghi nối tiếp hàng tỷ tin nhắn vào một tệp (file) duy nhất ngày này qua tháng nọ, tệp đó sẽ phình to lên đến hàng tỷ Terabyte. Để giải quyết vấn đề này Kafka sử dụng kết hợp 2 khái niệm: Segment (Phân đoạn) và Index (Chỉ mục)
-
🗂️ Segments (Phân đoạn): Thay vì nối dài một tệp duy nhất, Kafka "chặt" nhật ký ra thành nhiều tệp nhỏ hơn (mặc định thường là 1GB một tệp). Tệp đang được ghi hiện tại gọi là active segment, còn các tệp trước đó đã đóng lại và chỉ dùng để đọc.
- Lợi ích dọn dẹp: Khi dữ liệu cũ hết hạn (ví dụ bạn cài đặt giữ dữ liệu trong 7 ngày), Kafka không cần phải vất vả sửa đổi tệp. Nó chỉ đơn giản là ra lệnh xóa thẳng (delete) toàn bộ các tệp segment cũ khỏi hệ điều hành. Rất nhanh và sạch sẽ!
-
🔍 Indexes (Chỉ mục): Để Consumer không phải dò tìm từng dòng khi muốn đọc lại một tin nhắn ở một vị trí cũ, mỗi segment sẽ đi kèm với các tệp chỉ mục. Tệp chỉ mục này hoạt động giống như mục lục sách, ánh xạ trực tiếp số thứ tự của tin nhắn (Offset) sang vị trí byte vật lý trên ổ cứng. Nhờ vậy, Kafka có thể nhảy thẳng đến đúng vị trí cần đọc ngay lập tức.
2. Tuyệt kỹ luân chuyển (Zero-copy) 🚀
Như vậy là khâu "Lưu trữ" đã được tối ưu rất tốt. Bây giờ chúng ta chuyển sang khâu "Đọc" (Gửi dữ liệu cho Consumer).
Khi có yêu cầu đọc dữ liệu, theo cách thông thường của máy tính, dữ liệu sẽ đi một vòng rườm rà: Ổ cứng -> Bộ nhớ đệm hệ điều hành (OS Cache) -> Vùng nhớ của ứng dụng Kafka (User space) -> Bộ đệm Socket -> Card mạng. Quá trình này đòi hỏi sao chép dữ liệu nhiều lần.
Kafka bỏ qua sự rườm rà này bằng một kỹ thuật gọi là Zero-copy (sử dụng system call sendfile). Dữ liệu được lệnh truyền thẳng từ OS Cache ra card mạng, hoàn toàn đi tắt qua vùng nhớ của ứng dụng Kafka.
Việc bỏ qua bước đưa dữ liệu vào vùng nhớ của ứng dụng (kỹ thuật Zero-copy) giúp Kafka giải phóng được hai tài nguyên phần cứng cực kỳ quan trọng: CPU và RAM (đặc biệt là bộ nhớ của ứng dụng Java).
Hãy cùng so sánh để thấy sự khác biệt nhé:
-
🐌 Cách đọc dữ liệu thông thường: Dữ liệu sẽ đi từ Ổ cứng ➡️ Bộ nhớ đệm của hệ điều hành (OS Cache) ➡️ Vùng nhớ của ứng dụng Kafka ➡️ Bộ đệm Socket (của OS) ➡️ Card mạng.
- Vấn đề: Quá trình này bắt CPU phải trực tiếp làm "phu khuân vác", sao chép dữ liệu qua lại nhiều lần giữa vùng của hệ điều hành và vùng của ứng dụng. Đồng thời, nó tạo ra một lượng rác khổng lồ trong RAM mà ứng dụng Java (Kafka) sau đó phải vất vả dọn dẹp (Garbage Collection).
-
🚀 Cách tiếp cận Zero-copy của Kafka: Kafka sử dụng một lệnh đặc biệt của hệ điều hành. Nó cơ bản nói với hệ điều hành rằng: "Hãy lấy đoạn dữ liệu này từ ổ cứng và chuyển thẳng ra card mạng giúp tôi".
- Kết quả: Dữ liệu đi từ Ổ cứng ➡️ OS Cache ➡️ Card mạng.
Nhờ đi tắt như vậy, CPU gần như được "giải phóng" hoàn toàn khỏi việc sao chép dữ liệu để tập trung vào việc quản lý hệ thống. RAM của ứng dụng cũng không bị phình to. Đó là lý do một máy chủ Kafka (Broker) có thể vắt kiệt băng thông của đường truyền mạng (ví dụ 10 Gbps) mà CPU chỉ mới hoạt động ở mức 10-20%.
Đến đây, chúng ta đã hiểu cách một máy chủ Kafka tối ưu hóa I/O để đạt tốc độ siêu tốc. Tuy nhiên, dù có tối ưu đến đâu, một cỗ máy vật lý cô độc vẫn luôn có "gót chân Achilles". Nếu hàng triệu tài xế cùng dội bom dữ liệu cùng một lúc, dung lượng ổ cứng sẽ cạn kiệt và băng thông mạng sẽ nghẽn cứng. Tồi tệ hơn, điều gì sẽ xảy ra nếu tia sét đánh trúng trung tâm dữ liệu và cỗ máy duy nhất đó cháy rụi? Toàn bộ thế giới ngầm của bạn sẽ sụp đổ.
Để cai trị lượng dữ liệu khổng lồ của thế giới thực, Kafka không bao giờ chiến đấu một mình. Nó vượt ra khỏi giới hạn của một vỏ bọc kim loại để dệt nên một mạng lưới phân tán vô hình và bất diệt.
Phần 2: Cơ chế Phân tán & Chống mất dữ liệu 🕸️
Trong Kafka, thay vì cố gắng nhồi nhét mọi dữ liệu vào một cuốn sổ khổng lồ, Kafka xé cuốn sổ đó ra thành hàng trăm phần nhỏ, gọi là cácPartition (Phân vùng), và rải đều chúng lên nhiều máy chủ khác nhau, chính vì thế dữ liệu của bạn (các Partition) không bao giờ chỉ nằm trơ trọi trên một máy chủ (Broker) duy nhất. Nó sẽ được sao chép ra nhiều máy chủ khác nhau. Cơ chế này hoạt động dựa trên mô hình Leader và Follower:
-
👑 Leader (Bản chính): Trong số các bản sao của một vách ngăn (Partition), sẽ có một máy chủ được bầu làm Leader. Tất cả các thao tác đọc và ghi dữ liệu từ ứng dụng của bạn đều bắt buộc phải đi qua Leader này.
-
👥 Followers (Bản sao phụ): Các máy chủ giữ bản sao còn lại được gọi là Follower. Nhiệm vụ duy nhất của chúng là liên tục sao chép (fetch) dữ liệu mới nhất từ Leader một cách thầm lặng, hệt như cách một Consumer đọc dữ liệu vậy.
Tuy nhiên, trong một hệ thống phân tán, đường truyền mạng có thể bị lag, hoặc một máy chủ Follower có thể đang quá tải dẫn đến việc sao chép bị chậm nhịp so với Leader.
Để kiểm soát việc này một cách chặt chẽ, Kafka duy trì một khái niệm cực kỳ quan trọng gọi là ISR (In-Sync Replicas - Danh sách các bản sao đồng bộ). Đây là một danh sách "tinh hoa" chỉ chứa Leader và những Follower đang bắt kịp sát nút với dữ liệu của Leader. Nếu một Follower bị tụt lại quá xa, nó sẽ bị "đá" ra khỏi danh sách ISR này.
Bây giờ, hãy thử đặt mình vào vị trí của người thiết kế hệ thống Kafka để xử lý tình huống khẩn cấp sau:
Giả sử máy chủ chứa Leader đột ngột bốc cháy và hệ thống phải ngay lập tức bầu ra một Leader mới để tiếp tục nhận dữ liệu. Theo bạn, Kafka sẽ ưu tiên chọn một Follower đang nằm trong danh sách ISR, hay một Follower nằm ngoài danh sách ISR để lên làm Leader mới? Vì sao lại như vậy?
Quyết định của Kafka đó chính là ưu tiên tuyệt đối một Follower nằm trong danh sách ISR.
Lý do cốt lõi nằm ở bài toán đánh đổi giữa Tính nhất quán (Consistency) và Tính sẵn sàng (Availability):
-
🛡️ Bầu Leader từ trong ISR (Ưu tiên tính nhất quán - Không mất dữ liệu): Các Follower trong ISR là những máy chủ đã bắt kịp tiến độ ghi dữ liệu của Leader cũ. Khi chọn một trong số chúng lên thay thế, hệ thống đảm bảo những tin nhắn đã được lưu trữ an toàn trước đó sẽ không bị mất đi. Đây là hành vi mặc định của Kafka.
-
⚠️ Bầu Leader ngoài ISR (Unclean Leader Election): Một Follower nằm ngoài ISR bản chất là một máy chủ đang bị "lag" và chưa kịp sao chép các tin nhắn mới nhất. Nếu nó được đưa lên làm Leader, nó sẽ biến kho dữ liệu (bị thiếu hụt) của mình thành "chân lý" mới của toàn hệ thống. Mọi máy chủ khác khi sống lại sẽ phải xóa bỏ dữ liệu mới để đồng bộ lùi theo Leader này. Kết quả: Dữ liệu bị mất vĩnh viễn.
Kafka cho phép bạn quyền quyết định thông qua cấu hình unclean.leader.election.enable. Nếu bạn đặt nó là true, bạn đang ra lệnh cho Kafka: "Nếu toàn bộ máy chủ trong ISR đều sập, hãy chọn đại một máy ngoài ISR lên làm Leader. Thà chấp nhận mất một ít dữ liệu để hệ thống tiếp tục phục vụ (tính sẵn sàng), còn hơn là sập toàn bộ".
Giờ chúng ta bàn về người "nhạc trưởng" đứng sau điều phối quá trình theo dõi và bầu Leader này.
Trong nhiều năm, Kafka không thể tự mình quản lý danh sách các Broker hay quyết định ai làm Leader. Nó phải dựa hoàn toàn vào một hệ thống phần mềm tách biệt có tên là ZooKeeper. Tuy nhiên, ở các phiên bản mới nhất, Kafka đã thực hiện một cuộc lột xác: loại bỏ ZooKeeper và dùng cơ chế quản lý nội bộ tên là KRaft (Kafka Raft).
Lí do cho cuộc chia tay lịch sử này đó chính là. Trước đây, ZooKeeper đóng vai trò là "bộ não" lưu trữ toàn bộ siêu dữ liệu (metadata) của Kafka: thông tin về Broker nào đang sống, ai là Leader của Partition nào, và cấu hình hệ thống ra sao.
Tuy nhiên, việc cõng thêm "người ngoài" này trên lưng gây ra 3 rắc rối chí mạng:
-
1. 🏋️ Nhân đôi gánh nặng vận hành: Các kỹ sư hệ thống phải cài đặt, cấu hình, bảo mật và giám sát cùng lúc hai hệ thống phân tán phức tạp (Kafka và ZooKeeper). Khi có lỗi xảy ra, việc truy vết lỗi chéo giữa hai hệ thống là một cơn ác mộng.
-
2. 🐌 Nút thắt cổ chai khi mở rộng: ZooKeeper không được thiết kế để xử lý dữ liệu thay đổi liên tục với khối lượng lớn. Khi một cụm Kafka phình to lên đến hàng trăm ngàn Partition, ZooKeeper trở nên quá tải. Nếu một Broker sập, việc ZK phải xử lý bầu lại hàng ngàn Leader cùng lúc mất rất nhiều thời gian (có thể lên tới vài phút), khiến dữ liệu bị ách tắc.
-
3. 🧩 Sự cồng kềnh trong kiến trúc: Kafka sinh ra để xử lý luồng sự kiện (event stream) dạng nhật ký (log), nhưng nó lại phải lưu siêu dữ liệu của mình trên ZooKeeper - một hệ thống lưu trữ dạng cây thư mục (tree-based). Sự bất đồng bộ này rất cồng kềnh.
Giải pháp đột phá: KRaft (Kafka Raft)
Kafka quyết định tự làm chủ vận mệnh của mình bằng kiến trúc KRaft. Thay vì dùng ZooKeeper, Kafka tự bầu ra một nhóm các máy chủ nội bộ gọi là Quorum Controllers. Điều thiên tài ở đây là: Kafka coi sự thay đổi siêu dữ liệu (metadata) cũng chỉ là một luồng sự kiện (event stream) thông thường, và nó dùng chính cơ chế cốt lõi của mình (append-only log) để lưu trữ và phân phối metadata này!
Kết quả là hệ thống phục hồi sau sự cố siêu nhanh (tính bằng mili-giây thay vì phút), và Kafka có thể mở rộng lên hàng triệu Partition một cách nhẹ nhàng.
Phần 3: Hoạt động ngầm của Producer & Consumer
1. Sự khôn ngoan của Producer
Hãy tưởng tượng bạn viết một ứng dụng (Producer) để bắn hàng triệu tin nhắn mỗi giây vào một Topic có 50 vách ngăn (Partitions) nằm rải rác trên 10 máy chủ (Brokers) khác nhau.
Theo bạn, ở ngay tại thời điểm bắn tin nhắn đi, gã Producer làm cách nào để tính toán và biết chính xác nó phải ném tin nhắn đó vào đúng Partition số mấy, trên Broker nào?
Có thể nói, đây thực sự là một trong những điểm "ăn tiền" nhất của Kafka mà không phải ai cũng để ý ngay từ đầu! 🧠
Sự thật là, Producer không hề nhắm mắt gửi bừa. Nó hoạt động vô cùng chủ động và thông minh qua hai bước cốt lõi sau:
Bước 1: Tải "Tấm bản đồ" (Metadata) 🗺️
Trước khi gửi đi tin nhắn đầu tiên, Producer sẽ kết nối vào cụm Kafka và xin một "tấm bản đồ" (gọi là Metadata). Tấm bản đồ này cho nó biết chính xác Topic đó có bao nhiêu Partition, và Leader của từng Partition hiện đang nằm trên Broker (máy chủ) nào. Nó sẽ lưu tấm bản đồ này vào bộ nhớ của nó và thỉnh thoảng cập nhật lại.
Bước 2: Quyết định điểm đến (Routing/Partitioning) 🔀
Khi "bóp cò" gửi tin nhắn, Producer sẽ đưa tin nhắn qua một bộ phận gọi là Partitioner. Bộ phận này sẽ dùng một thuật toán để quyết định xem tin nhắn vào Partition nào. Có 2 kịch bản chính:
-
🔑 Kịch bản có Khóa (Key): Giả sử tin nhắn của bạn đính kèm một Key (ví dụ: user_id = 123). Producer sẽ băm (hash) cái Key này ra một con số, rồi chia lấy dư cho tổng số Partition.
-
Công thức:
Hash(Key) % Số_lượng_Partition = Vị trí Partition. -
Phép màu: Nhờ toán học, bất kỳ tin nhắn nào có cùng user_id = 123 cũng sẽ luôn luôn rớt vào cùng một Partition duy nhất!
-
-
🎲 Kịch bản không có Khóa (No Key): Nếu tin nhắn chỉ có dữ liệu (Value) mà không có Key, Producer sẽ chia bài theo kiểu "xoay vòng" (Round-robin) hoặc "dính" (Sticky Partitioning - gom một mẻ gửi vào một Partition cho tiện rồi mới đổi sang Partition khác). Việc này giúp rải đều tải ra các máy chủ.
Bây giờ, hãy thử áp dụng cơ chế này vào thực tế nhé!
Giả sử bạn đang xây dựng hệ thống theo dõi vị trí cho một ứng dụng gọi xe. Bạn có các sự kiện tọa độ GPS của một tài xế liên tục gửi về theo thời gian thực: t1 (vị trí 1) ➡️ t2 (vị trí 2) ➡️ t3 (vị trí 3).
Theo bạn, để Consumer (Hệ thống Bản đồ) khi đọc dữ liệu không bị đọc sai thứ tự (ví dụ: xe đang chạy bỗng nhảy lùi về vị trí cũ rồi lại giật lên phía trước), chúng ta BẮT BUỘC phải chọn kịch bản gửi tin nhắn có Khóa (Key) hay không có Khóa? Và Khóa đó nên là gì?
Chúng ta cùng "mổ xẻ" vấn đề này nhé. Để đảm bảo quỹ đạo di chuyển của xe mượt mà và không bị xáo trộn, chúng ta BẮT BUỘC phải dùng kịch bản có Khóa (Key).
Nguyên nhân bắt nguồn từ một "định luật" cốt lõi của Kafka: Kafka chỉ đảm bảo thứ tự của các tin nhắn nằm TRONG CÙNG MỘT Partition. Hãy xem điều gì xảy ra ở hai kịch bản:
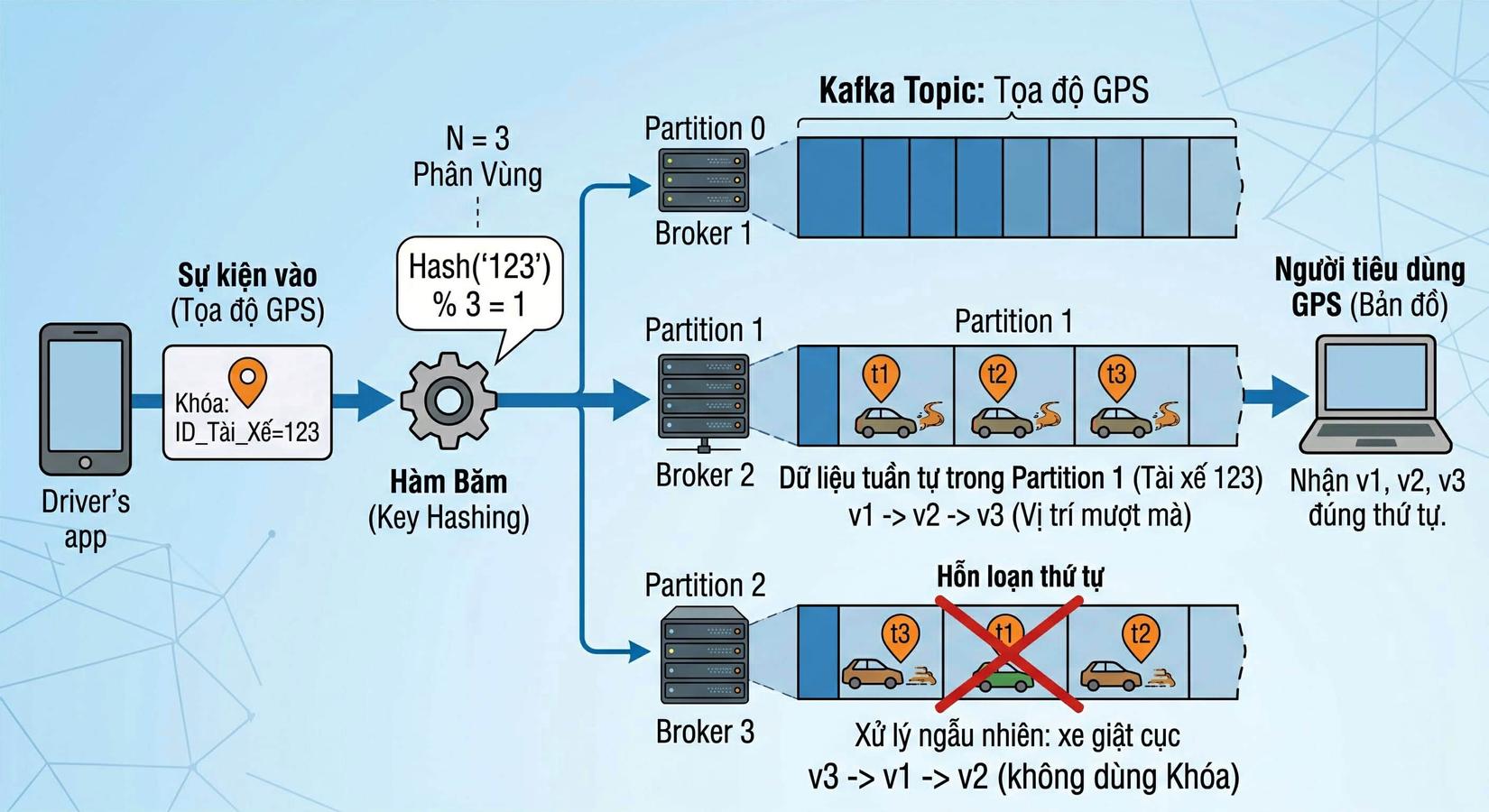
-
❌ Nếu không dùng Key: Tin nhắn tọa độ sẽ được rải ngẫu nhiên (Round-robin) vào các Partition khác nhau. Tọa độ t1 có thể bay vào Partition 2, t2 bay vào Partition 0, và t3 bay vào Partition 1. Vì các Partition được Consumer xử lý độc lập, việc đọc dữ liệu có thể dẫn đến hỗn loạn thứ tự (ví dụ: đọc được t3 rồi mới đến t1, t2). Hệ quả là quá trình xử lý sẽ ngẫu nhiên, làm vị trí xe trên bản đồ hiển thị kiểu "giật cục" (v3 -> v1 -> v2).
-
✅ Nếu dùng Key: Chúng ta sẽ chọn Key chính là ID của tài xế (Ví dụ: ID_Tai_Xe=123). Dựa vào công thức của Hàm băm: Hash('123') % Số_Partition (N=3), kết quả trả về ví dụ là 1. Lúc này, tất cả tọa độ GPS của tài xế '123' sẽ luôn luôn rớt vào một Partition duy nhất là Partition 1. Khi đó, dữ liệu tuần tự trong Partition 1 sẽ được xếp hàng ngay ngắn đúng trình tự thời gian (t1 -> t2 -> t3). Nhờ vậy, Người tiêu dùng GPS (Bản đồ) sẽ nhận được vị trí v1, v2, v3 đúng thứ tự, giúp hình ảnh xe di chuyển mượt mà.
2. Định luật thép của Consumer Group
Kafka xử lý dữ liệu khổng lồ bằng cách cho phép nhiều Consumer hợp sức lại thành một Consumer Group (Nhóm tiêu thụ) để chia sẻ khối lượng công việc.
Giả sử Topic của chúng ta có 50 Partitions. Nếu chỉ có 1 Consumer, nó phải đọc cả 50. Nếu ta thêm nhiều Consumer vào nhóm, Kafka sẽ tự động chia đều số Partition này ra (quá trình này gọi là Rebalance).
Bây giờ, hãy thử tài suy luận của bạn về cách Kafka phân chia công việc nhé:
Nếu Topic có 50 Partitions, và chúng ta mở rộng Consumer Group lên thành 50 máy Consumer (mỗi máy xử lý 1 Partition, rất hoàn hảo). Nhưng nếu dữ liệu vẫn đổ về quá nhiều và bạn quyết định chạy thêm máy Consumer thứ 51 vào nhóm đó. Theo bạn, máy thứ 51 này sẽ đọc dữ liệu từ Partition nào?
Câu trả lời ngắn gọn và phũ phàng là: Máy Consumer thứ 51 sẽ... ngồi chơi xơi nước (nhàn rỗi hoàn toàn)!
Để hiểu tại sao, chúng ta cần biết Kafka có một "bộ luật thép" trong việc phân chia công việc:
Trong cùng một Consumer Group, một Partition chỉ được phép phân công cho TỐI ĐA MỘT Consumer tại một thời điểm.
Lý do đằng sau luật thép này chính là để bảo vệ thành quả của Producer mà chúng ta vừa bàn ở trên: Đảm bảo thứ tự tuyệt đối.
Hãy tưởng tượng nếu Kafka cho phép 2 máy Consumer cùng xâu xé đọc chung 1 Partition. Chúng sẽ chạy đua với nhau (race condition). Máy A có thể chộp được sự kiện "Thanh toán" và xử lý xong chớp nhoáng, trước cả khi máy B kịp xử lý xong sự kiện "Tạo đơn". Như vậy, trật tự thời gian bị phá vỡ hoàn toàn!
Vì vậy, Kafka thà để máy thứ 51 thất nghiệp chứ tuyệt đối không đánh đổi sự chính xác của dữ liệu. Số lượng Consumer chạy đồng thời và sinh ra hiệu quả trong một nhóm sẽ luôn bị giới hạn bởi số lượng Partition của Topic đó.
Tuy nhiên, gã Consumer thứ 51 đang "ngồi chơi" này không hề vô dụng.
Hãy thử tưởng tượng trong một hệ thống thực tế đang vận hành ở cường độ cao. Nếu máy Consumer số 1 (đang phụ trách Partition số 1) đột ngột bị mất điện hoặc treo máy, hệ thống Kafka sẽ làm gì với gã Consumer thứ 51 đang nhàn rỗi kia để cứu vãn tình hình?
Đây chính là lúc máy Consumer nhàn rỗi kia phát huy tác dụng thực sự của nó!
Để quản lý việc này, Kafka có một cơ chế theo dõi sức khỏe gọi là Heartbeat (nhịp tim) ❤️. Mỗi máy Consumer trong nhóm phải liên tục gửi tín hiệu "tôi vẫn đang hoạt động tốt" về cho hệ thống quản lý của Kafka.
Nếu máy số 1 đột ngột bị đứt cáp mạng hoặc mất điện, nó sẽ ngừng gửi nhịp tim. Kafka nhận ra điều này ngay lập tức và đưa ra quyết định xử lý:
-
Loại bỏ: Kafka gạch tên máy số 1 ra khỏi Consumer Group.
-
Kích hoạt Rebalance (Tái cân bằng) ⚖️: Kafka tạm dừng toàn bộ việc đọc dữ liệu trong chớp nhoáng để sắp xếp lại công việc. Nó lấy Partition số 1 đang bị bỏ trống và lập tức "trao ấn kiếm" cho máy thứ 51 đang ngồi chơi xơi nước.
Nhờ quá trình Rebalance tự động này, máy số 51 đóng vai trò như một phương án dự phòng (hot standby). Dữ liệu ở Partition số 1 tiếp tục được xử lý mà không cần bất kỳ sự can thiệp thủ công nào từ kỹ sư hệ thống.
Phần 4: Hành trình sinh tử của một tin nhắn (Message)
Chặng 1: Bóp cò và Lời hứa của Kafka (Producer acks)
Như chúng ta đã biết ở phần trước, Producer sẽ băm Khóa (Key) để tìm ra đúng Partition và nhắm thẳng vào máy chủ Leader để gửi tin nhắn.
Tuy nhiên, gửi đi là một chuyện, làm sao Producer biết tin nhắn của mình đã được lưu trữ an toàn hay chưa? Nếu máy chủ Leader nhận tin nhắn xong, chưa kịp chép sang các Follower mà đột ngột bị rút phích cắm điện thì sao?
Để kiểm soát rủi ro này, Kafka cung cấp một thông số cấu hình cực kỳ quan trọng cho Producer gọi là acks (Acknowledgments - Tín hiệu xác nhận). Bạn có 3 mức độ để lựa chọn:
-
📨 acks=0 (Bắn và quên): Producer cứ đẩy dữ liệu đi qua mạng và không thèm chờ máy chủ Kafka phản hồi lại.
-
👍 acks=1 (Leader xác nhận): Producer sẽ đợi cho đến khi máy chủ Leader ghi thành công tin nhắn vào ổ cứng của riêng nó. Leader ghi xong là Producer yên tâm gửi tin tiếp theo, không quan tâm các Follower đã chép được hay chưa.
-
🤝 acks=all (Tất cả cùng xác nhận): Producer yêu cầu máy chủ Leader phải đợi đến khi tất cả các máy chủ Follower đang nằm trong danh sách đồng bộ (ISR) sao chép thành công tin nhắn, thì Leader mới được phép báo về cho Producer là "Đã nhận an toàn".
Bây giờ, hãy thử tưởng tượng bạn đang thiết kế hệ thống lõi cho một Ngân hàng, xử lý sự kiện "Khách hàng chuyển khoản 1 tỷ đồng".
Theo bạn, chúng ta BẮT BUỘC phải dùng cấu hình acks nào ở trên để đảm bảo giao dịch không bao giờ bị mất (ngay cả khi máy chủ Leader sập cháy ngay sau khi nhận tin)? Và khi chọn cấu hình an toàn nhất đó, hệ thống của bạn sẽ phải chấp nhận sự đánh đổi (nhược điểm) nào về mặt hiệu năng?
Để bảo vệ những giao dịch "tiền tỷ" không bao giờ bị bốc hơi, chúng ta bắt buộc phải chọn acks=all (trong một số phiên bản gọi là acks=-1).
Chúng ta cùng phân tích lý do và sự đánh đổi:
1. Tại sao không thể dùng acks=1?
Nếu bạn dùng acks=1, ngay khi máy chủ Leader ghi xong tin nhắn vào đĩa của nó, nó sẽ lập tức báo về cho Producer: "Thành công!". Producer yên tâm đóng giao dịch. Nhưng chỉ 1 mili-giây sau, Leader đột ngột chập cháy. Lúc này, các máy chủ Follower chưa kịp chép dữ liệu sang. Khi Kafka bầu một Follower lên làm Leader mới, giao dịch 1 tỷ đó hoàn toàn không tồn tại trong hệ thống. Dữ liệu bị mất vĩnh viễn!
2. Sự bảo vệ tuyệt đối của acks=all
Khi dùng acks=all, Leader bị bắt buộc phải chờ đợi. Nó chỉ được phép báo "Thành công" cho Producer khi tất cả các máy chủ Follower trong danh sách ISR đều đã sao chép và lưu trữ dữ liệu an toàn. Dù Leader có bốc cháy ngay sau đó, bất kỳ Follower nào được đưa lên làm Leader mới cũng đã có sẵn bản sao của giao dịch này.
3. Sự đánh đổi đắt giá: Độ trễ (Latency) 🐢
Cái giá phải trả cho sự an toàn tuyệt đối chính là thời gian. Thay vì chỉ mất thời gian kết nối mạng đến 1 máy chủ, Producer giờ đây phải đứng chờ tín hiệu đi một vòng rườm rà:
- Producer gửi tin đến Leader.
- Leader chờ các Follower kéo (fetch) dữ liệu về.
- Follower ghi xuống đĩa rồi báo cáo lại cho Leader.
- Leader tổng hợp đủ báo cáo rồi mới trả lời Producer.
Quá trình này làm tăng độ trễ (latency) của từng tin nhắn lên gấp nhiều lần, khiến tổng số lượng tin nhắn gửi được trong một giây (thông lượng - throughput) giảm đi đáng kể.
Chặng 2: Đánh dấu trang sách (Consumer Offsets)
Bây giờ, tin nhắn "chuyển khoản 1 tỷ" đã nằm an toàn tuyệt đối trong kho chứa của Kafka. Đã đến lúc ứng dụng của chúng ta (Consumer) vào đọc tin nhắn đó để thực hiện lệnh trừ tiền.
Kafka lưu hàng tỷ tin nhắn. Để Consumer biết mình đã đọc đến đâu (tránh đọc lại từ đầu hoặc đọc sót), Kafka sử dụng một con số thứ tự gọi là Offset (hoạt động hệt như một cái kẹp đánh dấu trang sách 🔖).
Khi Consumer đọc xong một tin nhắn, nó có trách nhiệm "Commit" (chốt) cái Offset này lại để báo cho Kafka biết: "Tôi đã xử lý xong tin nhắn số 100, lần sau hãy đưa tôi tin số 101".
Giả sử Consumer vừa đọc được tin nhắn "Chuyển khoản 1 tỷ", nó lập tức kết nối với Core Banking và đã trừ xong 1 tỷ trong tài khoản khách hàng. Nhưng ngay khoảnh khắc nó chuẩn bị gửi lệnh Commit Offset về cho Kafka để xác nhận hoàn tất, máy Consumer đột ngột bị đứt nguồn điện.
Chúng ta cùng mổ xẻ thảm họa này nhé! Đây là một trong những cạm bẫy kinh điển nhất khi làm việc với các hệ thống phân tán.
Vì máy Consumer đầu tiên bị sập trước khi kịp gửi lệnh Commit, "chiếc kẹp trang sách" (Offset) trong hệ thống Kafka vẫn nằm nguyên ở vị trí cũ chưa hề được nhích lên.
Khi máy Consumer dự phòng được gọi lên thay thế, nó sẽ hỏi Kafka: "Tôi nên bắt đầu đọc từ đâu?". Kafka trả lời: "Hãy đọc từ vị trí Offset cuối cùng được lưu lại".
Và thế là chuỗi thảm họa bắt đầu:
-
🔄 Đọc lại tin nhắn cũ: Máy dự phòng sẽ đọc lại chính cái tin nhắn "Chuyển khoản 1 tỷ" đó một lần nữa (vì Kafka tưởng tin nhắn này chưa được ai xử lý xong).
-
💸 Trừ tiền kép (Duplicate Processing): Máy dự phòng lại hồn nhiên kết nối với Core Banking và thực hiện lệnh trừ thêm 1 tỷ nữa. Kết quả là khách hàng thực hiện lệnh chuyển 1 tỷ nhưng tài khoản bị trừ tận 2 tỷ!
Hiện tượng này được gọi là cơ chế phân phối "At-Least-Once" (Ít nhất một lần). Nghĩa là hệ thống thà giao tin nhắn nhiều lần để đảm bảo không bị sót, còn hơn là bị mất dữ liệu.
Tuy nhiên, đối với các giao dịch tài chính, việc xử lý lặp lại là điều tối kỵ. Để ngăn chặn thảm họa trừ tiền kép này, bản thân Consumer hoặc hệ thống ngân hàng (Core Banking) ở phía sau phải tự bảo vệ mình.
Theo bạn, ứng dụng Consumer hoặc hệ thống Core Banking cần có thêm một bước kiểm tra (hoặc cơ chế ghi nhớ) như thế nào trước khi thực sự bấm nút "trừ tiền", để đảm bảo rằng dù có nhận được cùng một tin nhắn 2 hay 100 lần đi nữa thì nó cũng chỉ thực thi đúng 1 lần duy nhất?
Phần 5: Tính lũy đẳng (Idempotency)
Để giải quyết triệt để thảm họa "trừ tiền kép" này, chúng ta cần trang bị cho hệ thống một khái niệm tối quan trọng: Tính lũy đẳng (Idempotency).
Lũy đẳng là một thuật ngữ toán học và khoa học máy tính, hiểu đơn giản là: Dù bạn có thực hiện một hành động 1 lần hay 100 lần, thì kết quả cuối cùng vẫn giống y hệt như khi bạn thực hiện nó 1 lần duy nhất.
Để đạt được sự hoàn hảo này trong Kafka, chúng ta phải thiết lập chốt chặn ở cả hai đầu của hệ thống:
Dưới đây là cách chúng ta "mổ xẻ" và áp dụng cơ chế này vào hệ thống ngân hàng:
1. 🛡️ Đầu vào (Producer - Ngăn chặn nhân bản dữ liệu):
Khi mạng chập chờn, Producer có thể tự động gửi lại cùng một tin nhắn nhiều lần. Bằng cách bật cấu hình enable.idempotence=true, Kafka sẽ âm thầm gán cho Producer một mã định danh (Producer ID) và đánh số thứ tự (Sequence Number) cho từng tin nhắn.
Cơ chế kiểm tra thì rất đơn giản:
-
Producer ID (Mã định danh): Giúp máy chủ Kafka nhận diện được tin nhắn này đến từ ứng dụng Producer nào.
-
Sequence Number (Số thứ tự): Mỗi tin nhắn do Producer đó gửi đi sẽ được đánh số đếm tăng dần (0, 1, 2, 3...).
Ở phía máy chủ Kafka (Broker) sẽ duy trì một bộ đệm lưu lại Sequence Number lớn nhất mà nó đã nhận và ghi thành công từ mỗi Producer ID.
Giả sử máy chủ Kafka vừa lưu thành công một tin nhắn có Producer ID = 123 và Sequence Number = 5. Vài giây sau, do Producer không nhận được phản hồi nên đã gửi lại một request chứa tin nhắn y hệt, mang Producer ID = 123 và Sequence Number vẫn là 5.
Nhưng nhờ hai "tấm thẻ bài" này, máy chủ Kafka có thể nhận diện chính xác tin nhắn đến từ ứng dụng nào và đang ở số thứ tự bao nhiêu. Nếu phát hiện một số thứ tự đã được lưu trữ thành công trước đó, Kafka sẽ tự động loại bỏ bản sao bị trùng gửi tới. Còn nếu Producer tự ý tăng số thứ tự lên, máy chủ sẽ tưởng đó là một tin nhắn hoàn toàn mới.
Vậy còn về cơ chế gửi lại thì sao, đây là một điểm rất tiện lợi của hệ sinh thái Kafka. bạn không cần phải tự viết logic gửi lại (ví dụ như các vòng lặp while hay try-catch phức tạp) ở dưới backend. Thư viện Kafka Client mà bạn cài đặt (như Java, Python, Go) đã tự động đảm nhiệm toàn bộ cơ chế retry này ở dưới nền ngay khi bạn cấu hình bật tính năng lũy đẳng ⚙️.
Tuy nhiên, nếu cáp mạng bị đứt hoàn toàn, thư viện Kafka Client không thể cứ âm thầm gửi lại mãi mãi và làm treo toàn bộ ứng dụng backend của bạn được. Theo bạn, chúng ta cần cài đặt thêm cho Producer thông số giới hạn nào để nó biết khi nào nên "bỏ cuộc" và ném ra một lỗi (Exception) cho lập trình viên xử lý?
Bật mí cho bạn nhé, để kiểm soát việc thư viện Kafka Client tự động "bỏ cuộc", chúng ta sẽ cấu hình các thông số giới hạn sau cho Producer:
-
⏱️ delivery.timeout.ms (Thời gian chờ tối đa): Đây là thông số quan trọng và phổ biến nhất. Nó quy định tổng thời gian mà Producer được phép cố gắng hoàn thành việc gửi một tin nhắn (bao gồm cả lần gửi đầu tiên và tất cả các lần retry). Ví dụ, nếu bạn cài đặt là 120.000 ms (2 phút), thư viện sẽ tự động gửi lại liên tục dưới nền. Nếu quá 2 phút mà vẫn thất bại, nó mới chịu dừng lại và ném ra lỗi (Exception) cho ứng dụng backend của bạn xử lý.
-
🔄 retries (Số lượng lần thử): Thông số này giới hạn số lần gửi lại tối đa. Tuy nhiên, ở các hệ thống Kafka hiện đại, kỹ sư thường để thông số này ở mức cực lớn và ưu tiên kiểm soát bằng thời gian (delivery.timeout.ms) để linh hoạt hơn.
-
⏳ retry.backoff.ms (Thời gian nghỉ ngơi): Để tránh việc "dội bom" request liên tục vào một máy chủ đang bị quá tải, thông số này quy định khoảng thời gian chờ (ví dụ: 100ms) giữa hai lần gửi thử liên tiếp.
Khi Producer ném ra lỗi (Exception) do hết thời gian chờ, điều đó đồng nghĩa với việc tin nhắn không thể tới đích.
2. 🛡️ Đầu ra (Consumer - Ngăn chặn xử lý kép):
Ngay cả khi kho lưu trữ của Kafka hoàn toàn sạch sẽ, máy Consumer vẫn có thể đọc lại tin nhắn cũ nếu nó bị sập trước khi kịp chốt Offset. Để bảo vệ đầu ra, bản thân ứng dụng Consumer (hoặc Database) phải tự thiết lập 3 bước kiểm tra:
-
Gắn thẻ định danh: Khi Producer gửi tin nhắn "Chuyển khoản 1 tỷ", nó phải đính kèm một mã độc nhất vô nhị, ví dụ:
Transaction_ID = TX-999. -
Sổ ghi nhớ của Consumer: Hệ thống Core Banking (hoặc Database của Consumer) sẽ tạo một bảng chuyên lưu lại các Transaction_ID đã thực hiện thành công.
-
Chốt chặn kiểm tra: Khi Consumer dự phòng (máy số 51) nhận được lại tin nhắn TX-999, thay vì mù quáng trừ tiền ngay, nó phải làm một bước tra cứu:
-
Truy vấn: "Cái mã
TX-999này đã có trong sổ ghi nhớ chưa?" -
Kết quả là CÓ: Nghĩa là đây là tin nhắn cũ bị gửi lại do lỗi sập máy trước đó. Consumer sẽ bỏ qua việc trừ tiền, nhưng vẫn gửi lệnh Commit Offset về cho Kafka để Kafka "đóng hồ sơ" tin nhắn này lại.
-
Kết quả là KHÔNG: Consumer tiến hành trừ tiền, ghi
TX-999vào sổ ghi nhớ, và gửi lệnh Commit Offset. Kỹ thuật này thường được hiện thực hóa bằng Ràng buộc duy nhất (Unique Constraint) trong Database.
-
Như vậy, chúng ta đã biến một hệ thống có nguy cơ xử lý lặp (At-Least-Once) thành một hệ thống xử lý chính xác tuyệt đối ở đầu cuối.
Tuy nhiên, cách trên đòi hỏi chúng ta phải tự xây dựng cơ chế bảo vệ ở phía ứng dụng hoặc Database. Bản thân Kafka không cam chịu việc đùn đẩy trách nhiệm này. Kể từ phiên bản 0.11, Kafka đã tự trang bị một vũ khí hạng nặng để đạt được mức độ giao hàng hoàn hảo nhất: Exactly-Once Semantics (Chính xác một lần), áp dụng cực tốt khi bạn đọc dữ liệu từ Kafka, tính toán, rồi ghi kết quả vào một Topic Kafka khác.
Để làm được điều này, Kafka đã vay mượn một khái niệm kinh điển từ các hệ quản trị cơ sở dữ liệu (như MySQL, Oracle). Khái niệm này giúp gộp chung nhiều thao tác đọc/ghi lại với nhau thành một khối "sống cùng sống, chết cùng chết" (hoặc là thành công tất cả, hoặc là hủy bỏ tất cả).
Phần 6: Transactions (Giao dịch)! 🏛️
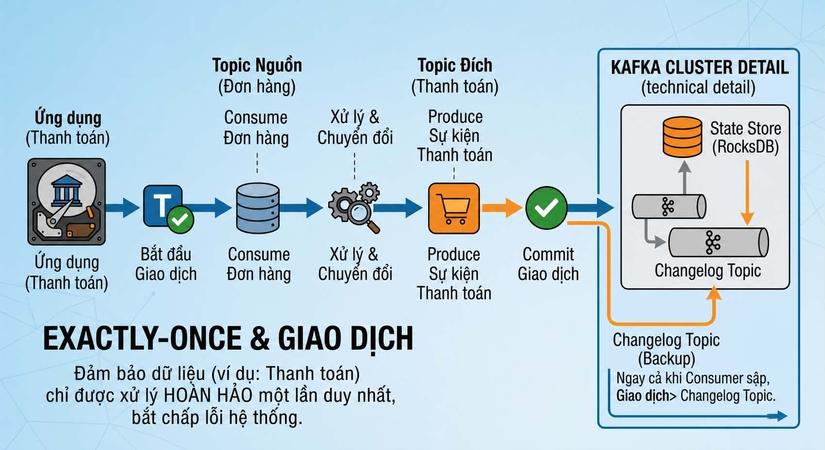
Giống hệt như trong các cơ sở dữ liệu truyền thống, Kafka cho phép bạn gom nhiều thao tác lại thành một khối thống nhất (atomic). Tính năng này đặc biệt tỏa sáng trong mô hình Read-Process-Write (Đọc - Xử lý - Ghi) – khi bạn đọc dữ liệu từ một Topic, biến đổi nó, rồi ghi kết quả sang một Topic khác.
Hãy xem cách nó giải quyết triệt để thảm họa "trừ tiền kép" khi hệ thống đang xử lý dở dang thì bị sập:
-
Mở Giao dịch: Ứng dụng báo với Kafka rằng nó chuẩn bị thực hiện một chuỗi hành động quan trọng.
-
Đọc & Tính toán: Ứng dụng đọc tin nhắn từ Topic A và thực hiện việc tính toán (ví dụ: trừ tiền).
-
Ghi Kết quả: Ứng dụng đẩy kết quả (biên lai) vào Topic B.
-
Đánh dấu hoàn tất: Ứng dụng gửi lệnh Commit Offset cho Topic A.
-
Chốt Giao dịch (Commit/Abort): Ứng dụng ra lệnh chốt hạ toàn bộ khối công việc.
Phép màu của Transactions nằm ở chỗ: Bước 3 và Bước 4 bị trói chặt vào nhau.
Nếu máy Consumer bị sập ngay trước Bước 5, Kafka sẽ tự động Hủy bỏ (Abort) toàn bộ giao dịch này. Những tin nhắn biên lai đã lỡ ghi vào Topic B sẽ bị đánh dấu là "chưa hoàn tất" và các Consumer khác sẽ không nhìn thấy chúng. Đồng thời, Offset ở Topic A không bị xê dịch. Khi máy dự phòng lên thay, nó sẽ đọc và xử lý lại từ đầu một cách sạch sẽ, không hề tạo ra dữ liệu rác hay bị xử lý lặp!
Đây chính là mảnh ghép cuối cùng giúp Kafka đạt được cảnh giới Exactly-Once Semantics (Chính xác một lần). 🎯
Các bạn còn nhớ bài toán về việc retry phía Producer chúng ta đã cùng bàn tới trong phần Tính Lũy Đẳng (Impodentency) không? Bây giờ, nếu chúng ta đang bọc hành động gửi tin nhắn này trong một khối Giao dịch (Transactions) "sống cùng sống, chết cùng chết", theo bạn, khi bắt được cái Exception đó, ứng dụng backend của chúng ta BẮT BUỘC phải gọi một lệnh gì để Kafka biết và dọn dẹp sạch sẽ toàn bộ dữ liệu dở dang của giao dịch này?
Khi bắt được lỗi (Exception) đó, ứng dụng backend của chúng ta bắt buộc phải gọi một lệnh là abortTransaction() (Hủy bỏ giao dịch).
- Lệnh
abortTransaction()của Producer giống như việc dán một cái nhãn "HÀNG LỖI - ĐỪNG DÙNG" (Control Message) lên lô hàng dở dang. 📦
Lúc này để Consumer đọc được những lô hàng đang bị gắn tag lỗi này và bỏ qua chúng. Kafka cung cấp cho chúng ta một cấu hình dành riêng cho Consumer có tên là isolation.level.
-
👀isolation.level = read_committed (Chỉ đọc dữ liệu đã chốt): Khi bạn cài đặt thông số này, Consumer sẽ tự động nhận diện và bỏ qua mọi tin nhắn thuộc về các giao dịch đang mở hoặc đã bị lệnh abortTransaction() hủy bỏ. Điều này đảm bảo các Consumer khác sẽ không nhìn thấy những tin nhắn dở dang này.
-
📖 isolation.level = read_uncommitted (Đọc tất cả - Mặc định): Nếu bạn không cấu hình thông số trên, Kafka mặc định cho phép Consumer đọc mọi thứ vừa được đẩy vào Partition, bao gồm cả những dữ liệu "rác" từ các giao dịch đã thất bại.
Dựa vào cơ chế như vậy, bạn có thể thấy được rằng việc quên cấu hình isolation.level = read_committed sẽ thực sự là một cơn ác mộng, nó sẽ phá nát hoàn toàn tính toàn vẹn dữ liệu cũng như khối kiến trúc trúc Exactly-Once mà bạn dày công xây dựng!
Phần 7: Hệ Sinh Thái Mở Rộng - Xử Lý Thời Gian Thực
1. Cơ chế nén nhật ký (Log Compaction)
Trước đó, chúng ta biết rằng Kafka dọn dẹp ổ cứng bằng cách xóa bỏ toàn bộ một Segment (phân đoạn) khi nó quá hạn (ví dụ: sau 7 ngày). Cách này rất tốt cho các luồng sự kiện như "nhật ký truy cập web" – nơi dữ liệu cũ không còn nhiều giá trị.
Nhưng có một kiểu dữ liệu khác: Dữ liệu trạng thái.
Hãy tưởng tượng bạn lưu trữ "Địa chỉ nhà" của người dùng. Một người dùng (Key) có thể chuyển nhà 5 lần trong năm qua. Nếu dùng cơ chế xóa theo thời gian, sau 7 ngày, hệ thống sẽ xóa sạch mọi thông tin và bạn sẽ mất luôn địa chỉ hiện tại của họ.
Để giải quyết, Kafka đưa ra cơ chế Log Compaction. Thay vì xóa dựa trên thời gian, cơ chế này quét qua nhật ký và chỉ giữ lại tin nhắn có giá trị mới nhất cho mỗi Khóa (Key). Các tin nhắn cũ có cùng Key sẽ bị xóa bỏ một cách âm thầm ở dưới nền để giải phóng ổ cứng.
Cách hoạt động này biến một Topic của Kafka trở nên giống hệt như một bảng trong cơ sở dữ liệu truyền thống (nơi các dòng bị ghi đè cập nhật).
Để xem cơ chế này hoạt động ra sao, chúng ta hãy thử một bài toán nhỏ nhé 🎮.
Giả sử bạn có một Topic lưu điểm số cao nhất của người chơi. Các tin nhắn có cấu trúc là (Key: Tên người chơi, Value: Điểm số) và bay vào hệ thống theo thứ tự thời gian như sau:
-
(Alice, 10)
-
(Bob, 20)
-
(Alice, 30)
-
(Bob, 15)
-
(Alice, 50)
Dựa vào quy luật "chỉ giữ lại giá trị mới nhất cho mỗi Khóa (Key)", theo bạn, sau khi Log Compaction chạy xong, trong ổ cứng của Kafka sẽ chỉ còn sót lại những tin nhắn nào?
Cỗ máy Log Compaction sẽ quét qua và giữ lại đúng 2 trạng thái mới nhất là (Alice, 50) và (Bob, 15). Mọi dữ liệu điểm số cũ đã được dọn dẹp gọn gàng để tiết kiệm không gian.
2. Schema Registry (Sổ thông dịch cấu trúc dữ liệu) 📜
Khác với các Database truyền thống (nơi bạn phải định nghĩa trước các cột là kiểu chữ hay kiểu số), bản thân Kafka hoàn toàn "mù" về nội dung tin nhắn. Đối với Kafka, một tin nhắn gửi vào chỉ là một chuỗi byte (byte array) vô nghĩa.
Hãy tưởng tượng rủi ro sau:
Team Producer đang gửi dữ liệu với cấu trúc JSON: {"tên": "Alice", "điểm": 50}. Vài tháng sau, một lập trình viên mới vào làm, tự ý sửa lại code thành {"họ_tên": "Alice", "điểm_số": 50}.
Ở đầu bên kia, Consumer (do một team khác quản lý) vẫn miệt mài tìm kiếm trường tên. Không tìm thấy, Consumer lập tức báo lỗi (Crash) và toàn bộ luồng xử lý bị sập! 💥
Để ngăn chặn thảm họa "ông nói gà, bà hiểu vịt" này, hệ sinh thái Kafka dùng một công cụ chạy độc lập gọi là Schema Registry. Nó hoạt động như một "Bản hợp đồng pháp lý" (thường dùng định dạng tối ưu như Avro hoặc Protobuf thay vì JSON):
-
Chốt hợp đồng: Bất kỳ cấu trúc dữ liệu nào muốn truyền qua Kafka đều phải được đăng ký lên Schema Registry.
-
Kiểm duyệt (Producer): Trước khi gửi tin, Producer phải đối chiếu với Schema Registry. Nếu cấu trúc không khớp hợp đồng, tin nhắn bị chặn lại ngay tại nguồn.
-
Thông dịch (Consumer): Consumer kết nối với Schema Registry để tải "từ điển" về, đảm bảo luôn dịch đúng chuỗi byte ra dữ liệu có ý nghĩa.
Trong thực tế, các ứng dụng luôn phải nâng cấp và thay đổi cấu trúc (quá trình này gọi là Schema Evolution).
Giả sử ứng dụng Consumer hiện tại đang chạy rất ổn định. Hôm nay, team Producer quyết định nâng cấp và thêm một trường mới là số_điện_thoại vào tin nhắn để chuẩn bị cho một tính năng trong tương lai.
Theo bạn, trên bản hợp đồng Schema Registry, trường số_điện_thoại này BẮT BUỘC phải được cài đặt là một trường Yêu cầu (Required) hay một trường Tùy chọn (Optional / Có giá trị mặc định) để đảm bảo ứng dụng Consumer phiên bản cũ vẫn đọc được tin nhắn mới mà không bị sập?
Nếu câu trả lời của bạn là "Tùy chọn" thì tư duy về kiến trúc hệ thống của bạn rất nhạy bén đấy.
Việc cài đặt trường số_điện_thoại là Tùy chọn (hoặc có giá trị mặc định) chính là chìa khóa để đạt được tính Tương thích tiến (Forward Compatibility).
Nhờ vậy, máy Consumer cũ (vốn đang dùng cuốn "từ điển" cũ) khi đọc thấy một trường lạ lẫm, nó sẽ áp dụng luật: "À, trường này là tùy chọn, mình không biết nó là gì thì cứ an toàn bỏ qua nó thôi". Nó sẽ tiếp tục đọc được trường tên và điểm như bình thường. Nếu bạn đặt nó là Yêu cầu (Required), Consumer cũ sẽ lập tức "đình công" và báo lỗi vì thấy cấu trúc dữ liệu không khớp với hợp đồng của nó!
3. Kafka Connect & Kafka Streams 🏭
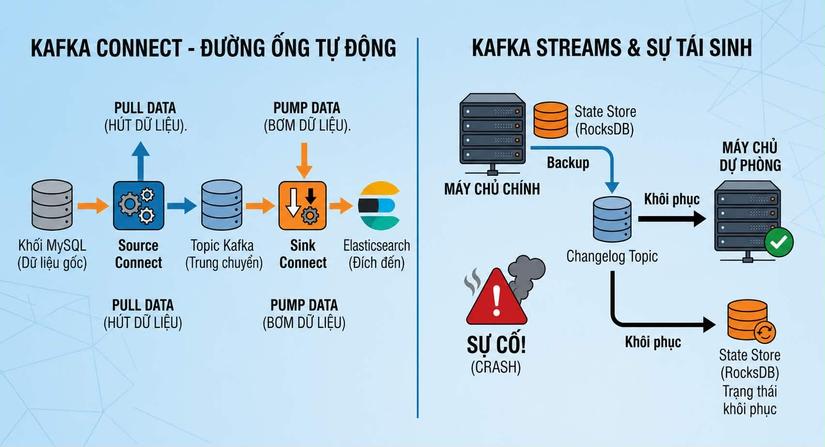 Bản thân lõi của Kafka (Kafka Core) rất "ngu ngơ", nó chỉ biết nhận, lưu và gửi chuỗi byte. Để thực sự biến nó thành trung tâm dữ liệu của toàn công ty, Kafka cung cấp thêm 2 công cụ đi kèm:
Bản thân lõi của Kafka (Kafka Core) rất "ngu ngơ", nó chỉ biết nhận, lưu và gửi chuỗi byte. Để thực sự biến nó thành trung tâm dữ liệu của toàn công ty, Kafka cung cấp thêm 2 công cụ đi kèm:
- Kafka Connect: Giống như những "đường ống bơm nước" có sẵn.
- Kafka Streams: Giống như "nhà máy lọc nước" thời gian thực.
Hãy thử đưa nó vào một bài toán thực tế nhé.
- Giả sử sếp giao cho bạn nhiệm vụ: "Hệ thống web cũ của công ty đang lưu thông tin khách hàng vào cơ sở dữ liệu MySQL. Từ hôm nay, cứ mỗi khi có một khách hàng mới được thêm vào bảng Users trong MySQL, em hãy tự động đẩy thông tin người đó sang Kafka ngay lập tức nhé".
Thay vì phải tự hì hục ngồi viết code cho một ứng dụng (Producer) kết nối vào MySQL, liên tục quét database xem có ai mới không rồi gửi lên Kafka... dựa vào định nghĩa ngắn gọn ở trên, bạn sẽ dùng Kafka Connect hay Kafka Streams để làm nhiệm vụ "hút" dữ liệu này (chỉ bằng vài dòng cấu hình mà không cần viết một dòng code nào)?
Kafka Connect chính là mảnh ghép dành cho bài toán này.
Thay vì phải tự viết một ứng dụng quét Database liên tục (vừa chậm vừa dễ gây quá tải cho MySQL), Kafka Connect hoạt động như những "đường ống nước" thông minh có sẵn. Nó được chia làm 2 loại:
-
Source Connect (Hút nước vào): Hút dữ liệu từ hệ thống khác (như MySQL, Oracle, MongoDB) đổ vào Kafka.
-
Sink Connect (Bơm nước ra): Lấy dữ liệu từ Kafka bơm ra các hệ thống lưu trữ khác (như Elasticsearch để tìm kiếm, hoặc Hadoop/Data Lake để phân tích).
Điều "ma thuật" nhất của Kafka Connect khi làm việc với Database (như MySQL) là nó không dùng lệnh SELECT để gom dữ liệu. Thay vào đó, nó dùng một kỹ thuật gọi là CDC (Change Data Capture).
Nó sẽ âm thầm đọc trực tiếp vào cuốn "nhật ký hệ thống" của MySQL (gọi là binlog). Bất cứ khi nào có một dòng dữ liệu mới được INSERT, UPDATE hay DELETE, Kafka Connect sẽ tóm gọn sự thay đổi đó theo thời gian thực và đẩy thành một sự kiện (event) vào Kafka. Cách này cực nhanh và gần như không ảnh hưởng đến hiệu năng của Database!
Bây giờ, dữ liệu người dùng từ MySQL đã chảy cuồn cuộn vào Kafka thông qua cái "ống nước" Kafka Connect rồi. Giờ là lúc chúng ta kích hoạt mảnh ghép còn lại: Kafka Streams (Nhà máy xử lý nước) 🏭.
Nếu Consumer bình thường chỉ đọc từng tin nhắn ra rồi xử lý đơn giản, thì Kafka Streams cho phép bạn làm những phép toán phức tạp ngay trên dòng chảy dữ liệu (Real-time Processing). Ví dụ:
-
Lọc (Filter): Chỉ giữ lại những người dùng ở "Hà Nội".
-
Gom nhóm (Group): Đếm xem có bao nhiêu người dùng mới đăng ký trong mỗi 5 phút.
Để tính toán được những thứ như "tổng số người dùng trong 5 phút qua", ứng dụng Kafka Streams bắt buộc phải có một "bộ nhớ tạm" (State) để cộng dồn các con số. Nhưng vì Kafka Streams thực chất cũng chỉ là một ứng dụng Java đang chạy trên một máy chủ, nếu máy chủ đó bị rút điện đột ngột, toàn bộ RAM sẽ bị xóa sạch.
Theo bạn, để không bị mất "bộ nhớ tạm" này khi hệ thống sập, Kafka Streams đã khôn khéo sao lưu những con số đang tính toán dở dang này vào đâu?
Bật mí luôn cho bạn nhé: Kafka Streams đã khôn khéo sao lưu dữ liệu vào chính bản thân hệ thống Kafka! 🤯
Người ta hay gọi đùa đây là hiện tượng "lấy mỡ nó rán nó" (eating your own dog food). Dưới đây là cách nó hoạt động:
-
Bộ nhớ cục bộ siêu tốc: Để tính toán nhanh, mỗi máy chủ Kafka Streams cài sẵn một cơ sở dữ liệu tí hon bên trong nó (thường là RocksDB). Khi đếm số người dùng, nó lưu con số này vào RocksDB.
-
Sao lưu thầm lặng: Mỗi khi con số trong RocksDB thay đổi (ví dụ: từ 5 lên 6), Kafka Streams lập tức gửi một tin nhắn sao lưu vào một Topic đặc biệt, ẩn bên trong Kafka gọi là Changelog Topic (Topic ghi nhận thay đổi).
-
Tái sinh từ đống tro tàn: Changelog Topic này được bật sẵn tính năng Log Compaction (giữ lại trạng thái mới nhất) và sao chép an toàn (Replication). Nếu máy chủ Streams bị cháy, máy dự phòng sẽ bật lên, đọc lại cái Changelog Topic này, và khôi phục lại y nguyên con số 6 vào RocksDB của nó rồi mới tiếp tục làm việc!
Như vậy, nhờ dựa vào sức mạnh lưu trữ bất diệt của Kafka Core, Kafka Streams có thể xử lý các bài toán phức tạp mà không bao giờ sợ mất kết quả giữa chừng.
Phần 8: Chốt chặn cuối cùng - (Security & MirrorMaker) 🛡️
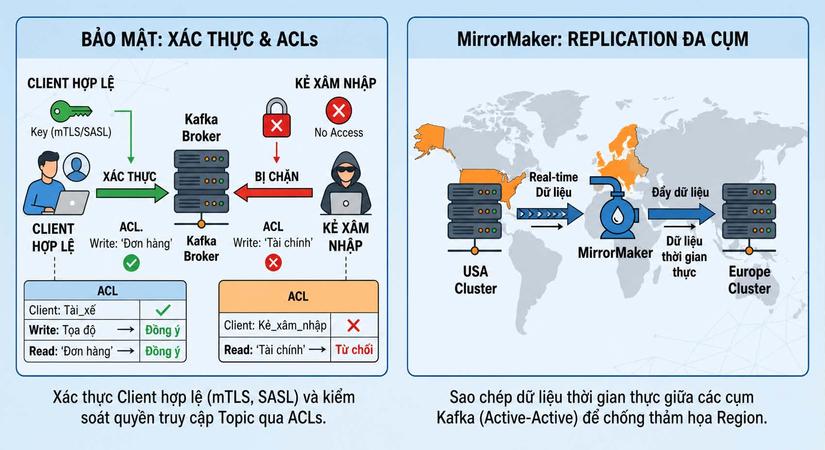
Khi bạn dựng Kafka chạy ở máy tính cá nhân, nó giống như một ngôi nhà mở toang cửa. Bất kỳ ai biết địa chỉ IP đều có thể gửi tin nhắn rác vào, hoặc kết nối Consumer để đọc trộm dữ liệu nhạy cảm.
Khi đưa lên Production (môi trường thực tế), bạn phải khóa ngôi nhà này lại bằng 2 lớp:
-
Xác thực (Authentication - "Anh là ai?"): Bắt buộc các Producer/Consumer phải trình "chứng minh thư" trước khi kết nối (thông qua các giao thức như SASL, hoặc chứng chỉ mTLS).
-
Phân quyền (Authorization - "Anh được làm gì?"): Dùng ACLs (Access Control Lists) để ra luật. Ví dụ: "Ứng dụng A chỉ được phép GHI vào Topic Đơn Hàng, tuyệt đối không được phép ĐỌC".
Và cuối cùng, bài toán thảm họa cấp độ cao nhất: Điều gì xảy ra nếu một trận động đất làm mất điện TOÀN BỘ trung tâm dữ liệu (Data Center) chứa cụm Kafka của bạn? Dù bạn có cấu hình acks=all hay có bao nhiêu bản sao đi nữa thì cũng vô dụng vì tất cả các máy chủ đều chung một tòa nhà.
Để đối phó, các tập đoàn lớn sử dụng một công cụ tên là MirrorMaker. Nhiệm vụ của nó là đứng giữa hai trung tâm dữ liệu (ví dụ một ở Hà Nội, một ở TP.HCM). Nó sẽ liên tục "hút" dữ liệu từ cụm Kafka ở Hà Nội và "bơm" bản sao sang cụm Kafka ở TP.HCM theo thời gian thực. Nhờ vậy, nếu Hà Nội mất điện, toàn bộ hệ thống của công ty sẽ tự động chuyển hướng giao dịch sang cụm TP.HCM mà không bị gián đoạn.
Phần 9: Những cạm bẫy chết người & Cách phòng tránh ☠️
Bây giờ, sau khi đã chuẩn bị hành trang là lượng kiến thức kha khá ở trên, chúng ta sẽ bước vào Trận chiến cuối (Mini-quiz)! ⚔️ Mình sẽ đưa ra các tình huống "đổ vỡ" thực tế ở cấp độ hóc búa, và bạn sẽ dùng chính những kiến thức vừa học để bắt bệnh nhé. Chúng ta bắt đầu với tình huống đầu tiên:
Tình huống 1: Vòng lặp tử thần (The Poison Pill) ☠️
Ngữ cảnh: Bạn quản lý một hệ thống xử lý Đơn hàng. Ứng dụng Consumer của bạn đang chạy rất mượt mà. Bỗng nhiên, một ứng dụng Producer phía đối tác bị lỗi và vô tình gửi vào Kafka một "tin nhắn độc hại" (ví dụ: một chuỗi JSON bị rách, hoặc thiếu hẳn trường giá_tiền quan trọng).
Diễn biến thảm họa:
-
Máy Consumer đọc trúng tin nhắn độc hại này.
-
Khi code của Consumer cố gắng lấy thông tin để tính toán, nó gặp lỗi nghiêm trọng (Exception) và Crash (sập) toàn bộ ứng dụng ngay lập tức.
-
Vì ứng dụng sập quá nhanh, nó chưa kịp Commit Offset (đánh dấu trang sách) cho tin nhắn này.
-
Hệ thống tự động khởi động lại máy Consumer.
-
Bật lên lại, Consumer hỏi Kafka: "Cho tôi đọc tiếp từ Offset cuối cùng nhé".
-
Kafka đưa lại đúng cái tin nhắn độc hại chưa được Commit kia. Consumer đọc lại, và... tiếp tục Crash! 💥
Hậu quả: Máy Consumer rơi vào một vòng lặp vô tận: Cứ bật lên là sập. Nó kẹt cứng vĩnh viễn tại vị trí đó, khiến hàng ngàn tin nhắn Đơn hàng hoàn toàn bình thường xếp hàng phía sau cũng bị tắc nghẽn, không thể nào được xử lý.
🔍 Câu hỏi dành cho bạn: Với tư cách là kỹ sư trưởng đang bị réo tên giữa đêm, bạn có những cách nào để "phá vỡ" vòng lặp tử thần này, giúp Consumer bỏ qua tin nhắn lỗi và tiếp tục xử lý dòng Đơn hàng đang bị kẹt phía sau? (Gợi ý: Bạn có thể can thiệp bằng code ở phía Consumer, hoặc can thiệp trực tiếp vào cơ chế "đánh dấu trang sách" của Kafka).
Nếu chưa có câu trả lời thì cũng không sao cả, đây là một trong những cái bẫy kinh điển nhất mà hầu như kỹ sư nào làm việc với Kafka cũng từng giẫm phải! Để "phá vỡ" vòng lặp này, chúng ta có hai cách giải quyết chính, từ cấp độ code đến cấp độ hệ thống:
Cách 1: Can thiệp bằng Code - Dùng Hàng đợi cách ly (Dead Letter Queue - DLQ)
Đây là cách giải quyết triệt để và chuyên nghiệp nhất. Thay vì để ứng dụng sập khi gặp lỗi, bạn bọc đoạn code xử lý tin nhắn bằng một khối try-catch. Nếu bắt được lỗi (Exception) do tin nhắn hỏng, Consumer sẽ làm 3 việc:
-
Không xử lý tin nhắn đó nữa.
-
Gửi nguyên xi tin nhắn hỏng đó sang một Topic đặc biệt khác gọi là DLQ (Hàng đợi cách ly) để kỹ sư phân tích sau.
-
Tiếp tục gửi lệnh Commit Offset cho Kafka để báo rằng: "Tôi đã xử lý xong (hoặc đã cách ly) tin nhắn này rồi, cho tôi đi tiếp".
Cách 2: Can thiệp thủ công bằng công cụ Kafka (Nhảy Offset) Nếu bạn không thể sửa code ngay lập tức, bạn phải can thiệp bằng tay:
-
Tạm tắt ứng dụng Consumer.
-
Dùng công cụ dòng lệnh của Kafka (CLI) can thiệp thẳng vào hệ thống, ra lệnh cộng thêm 1 vào con số Offset hiện tại của Consumer Group đó (ví dụ: chuyển từ 100 lên 101).
-
Bật ứng dụng lên lại. Consumer sẽ đọc từ 101, bỏ qua hoàn toàn cái tin nhắn độc hại nằm ở vị trí 100.
Tình huống 2: Tình thế Tiến thoái lưỡng nan (The Empty ISR) 🚨
Ngữ cảnh: Hệ thống của bạn có một Partition với 3 bản sao: Broker 1 (Leader), Broker 2 (Follower), và Broker 3 (Follower).
Diễn biến thảm họa:
-
Mạng nội bộ bị nghẽn, Broker 2 và 3 sao chép dữ liệu quá chậm nên bị Kafka "đá" văng khỏi danh sách đồng bộ (ISR). Lúc này trong nhóm tinh hoa ISR chỉ còn lại duy nhất Broker 1.
-
Xui xẻo thay, Broker 1 bị chập điện và cháy ổ cứng hoàn toàn.
-
Kafka từ chối bầu Broker 2 hoặc 3 lên làm Leader vì chúng không nằm trong ISR. Cả hệ thống đứng im, khách hàng không thể đặt xe.
-
Trong tình huống khẩn cấp, bạn quyết định bật cấu hình unclean.leader.election.enable = true để "ép" Broker 2 lên làm Leader mới để hệ thống tiếp tục chạy.
🔍 Câu hỏi dành cho bạn: Khi bạn đưa Broker 2 (một máy đang bị tụt hậu dữ liệu) lên làm Leader mới, điều tồi tệ gì sẽ xảy ra vĩnh viễn đối với những chuyến xe mà khách hàng đã đặt thành công trên Broker 1 ngay trước lúc nó bị cháy?
Chúng ta cùng mổ xẻ cơ chế khắc nghiệt này nhé! Đáp án chính xác và phũ phàng nhất ở đây là: Những chuyến xe đó sẽ bị MẤT VĨNH VIỄN (Permanent Data Loss). 📉
Dưới đây là chi tiết quá trình thảm họa diễn ra:
-
Sự thật bị che giấu: Khi Broker 1 nhận các chuyến xe cuối cùng, nó đã ghi vào ổ cứng nhưng chưa kịp truyền sang Broker 2 (vì Broker 2 đang bị lag và rớt khỏi nhóm ISR).
-
Vị Vua mới lên ngôi: Khi bạn ép Broker 2 lên làm Leader mới (unclean.leader.election.enable = true), Broker 2 chính thức trở thành "nguồn chân lý" (Source of Truth) mới của toàn bộ hệ thống. Nhưng khổ nỗi, trong bụng nó hoàn toàn không có thông tin về những chuyến xe vừa nãy.
-
Sự bốc hơi vĩnh viễn (Trích xuất nhật ký - Log Truncation): Giả sử ngày hôm sau, bạn sửa xong ổ cứng của Broker 1 và cắm nó trở lại cụm Kafka. Theo luật thép của hệ thống, Broker 1 lúc này bị giáng cấp xuống làm Follower. Để đồng bộ với Vua mới (Broker 2), Broker 1 sẽ tự động cắt bỏ và xóa sạch những chuyến xe mà Leader mới không có.
Thế là dữ liệu bốc hơi hoàn toàn khỏi cả 2 máy! Đây là sự đánh đổi kinh điển trong thiết kế hệ thống phân tán: Bạn thà hy sinh một vài dữ liệu cũ (Tính nhất quán - Consistency) để giữ cho toàn bộ hệ thống không bị "đóng băng" và tiếp tục nhận khách mới (Tính khả dụng - Availability).
Bây giờ, hãy đến với Tình huống 3 (Trùm cuối) để kết thúc chặng đường này nhé:
Tình huống 3: Bóng ma trong hệ thống (The Zombie Consumer) 🧟♂️
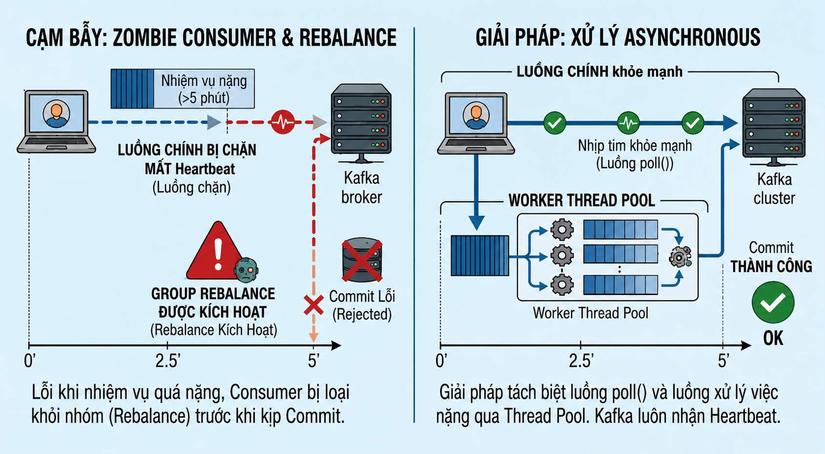
Ngữ cảnh: Bạn có một Consumer Group chuyên đọc tin nhắn "Xử lý video" từ Kafka. Máy Consumer A nhận được một tin nhắn yêu cầu render một video 4K. Công việc này rất nặng và mất khoảng 10 phút để chạy xong đoạn code tính toán.
Diễn biến thảm họa:
-
Kafka có một luật ngầm (max.poll.interval.ms - mặc định là 5 phút): Nếu trong vòng 5 phút mà Consumer không quay lại xin lấy tin nhắn mới, Kafka sẽ coi như máy Consumer đó đã "chết".
-
Khổ nỗi, máy A không chết, nó chỉ đang mải miết render video! Nhưng vì quá 5 phút, Kafka thẳng tay gạch tên máy A ra khỏi nhóm và kích hoạt quá trình Rebalance.
-
Kafka lấy chính cái tin nhắn "Xử lý video" đó giao cho máy dự phòng (Consumer B). Máy B bắt đầu quá trình render 10 phút.
-
Ở phút thứ 10, máy A xử lý xong, nó hồn nhiên gửi lệnh Commit Offset về cho Kafka để báo cáo hoàn thành. Nhưng Kafka từ chối và nói: "Anh đã bị đuổi khỏi nhóm, anh không có quyền Commit!". Máy A bị văng lỗi (Exception).
Hậu quả: Cả máy A và máy B cùng hì hục làm chung một việc nặng nhọc. Tài nguyên hệ thống bị nhân đôi lãng phí, và nếu việc này là "Trừ tiền" thì khách hàng lại bị trừ tiền 2 lần (dù ứng dụng không hề bị sập nguồn như Tình huống ở phần trước).
🔍 Câu hỏi dành cho bạn: Khi đối mặt với bài toán Consumer phải xử lý một tác vụ tốn quá nhiều thời gian (như gọi API bên thứ ba bị chậm, hoặc render file nặng), bạn có những cách cấu hình Kafka nào, hoặc có chiến thuật viết code nào ở phía Consumer để ngăn chặn việc Kafka hiểu lầm nó là "zombie" và gây ra thảm họa trên?
Đây là một bài toán vô cùng kinh điển khi Consumer phải gánh vác những tác vụ nặng nhọc. Để ngăn Kafka "hiểu lầm" máy A đã chết, chúng ta có 2 chiến thuật chính từ thấp đến cao:
1. Chiến thuật Cấu hình (Dễ làm nhưng có rủi ro) ⚙️
-
Cách làm: Tăng thông số max.poll.interval.ms (thời gian tối đa giữa 2 lần xin việc) lên cao hơn thời gian xử lý thực tế. Ví dụ, bạn biết render video mất tối đa 10 phút, bạn chỉnh thông số này thành 15 phút.
-
Sự đánh đổi: Nếu máy A bị đứt cáp mạng hoặc sập nguồn thật, Kafka sẽ phải ngồi im chờ ròng rã đúng 15 phút mới nhận ra lỗi để giao việc đó cho máy B. Hệ thống của bạn sẽ bị chậm trễ trong việc phát hiện lỗi.
2. Chiến thuật Viết Code (Kiến trúc chuẩn xác) 🧑💻
-
Cách làm: Tách biệt hoàn toàn việc "Nhận tin nhắn" và "Xử lý tin nhắn" (Xử lý bất đồng bộ - Asynchronous Processing). Bạn sẽ chia ứng dụng Consumer ra làm 2 luồng (Thread) chạy song song:
-
Luồng chính (Main Thread): Chỉ có một nhiệm vụ duy nhất là gọi hàm poll() liên tục để lấy tin nhắn mới và báo hiệu nhịp tim cho Kafka: "Tôi vẫn đang sống khỏe nhé".
-
Luồng phụ (Worker ThreadPool): Khi Luồng chính nhận được tin nhắn "Render Video", nó không tự làm mà ném ngay công việc đó sang cho một nhóm Luồng phụ xử lý.
Kết quả: Trong suốt 10 phút Luồng phụ hì hục render video, Luồng chính vẫn rảnh rỗi để liên tục chạy đi chạy lại báo cáo tình trạng sống với Kafka. Kafka sẽ thấy máy A vẫn hoạt động bình thường và không đá nó ra khỏi nhóm. Khi nào Luồng phụ báo "Tôi render xong rồi", Luồng chính mới đại diện gửi lệnh Commit Offset về cho Kafka để chốt hạ.
Phần kết: Ranh giới của sức mạnh – Khi nào cỗ máy nên ngủ yên?
Chúng ta cùng đổi gió một chút nhé. Trong thiết kế kiến trúc hệ thống, biết khi nào KHÔNG nên dùng một công cụ đôi khi còn quan trọng hơn là biết cách dùng nó.
Dù Kafka rất mạnh mẽ, hệ thống của bạn sẽ gặp rắc rối lớn nếu cố tình dùng nó trong 4 trường hợp sau:
-
🗄️ Hàng đợi công việc đơn giản (Simple Task Queue): Nếu bạn chỉ cần một hệ thống nhận việc, giao cho một máy trạm (worker) xử lý, và xóa ngay lập tức sau khi xong, Kafka không hề phù hợp. Như chúng ta đã biết, Kafka là một cuốn nhật ký (append-only log), nó không xóa từng tin nhắn riêng lẻ mà giữ lại để đọc nhiều lần. Thêm nữa, số lượng worker chạy đồng thời trong Kafka bị "khóa cứng" vào số lượng Partition, làm giảm đi sự linh hoạt nếu bạn muốn bật thêm hàng trăm worker lên cùng lúc.
-
🔍 Cơ sở dữ liệu truy vấn ngẫu nhiên (Ad-hoc Queries): Kafka không phải là cơ sở dữ liệu quan hệ (RDBMS) hay NoSQL (như MongoDB). Bạn không thể dễ dàng ném cho nó một câu lệnh như SELECT * FROM topic WHERE user_id = 123. Tìm kiếm ngẫu nhiên một dòng cụ thể trong một cuốn nhật ký khổng lồ là điều Kafka không sinh ra để làm.
-
📦 Truyền tải tệp tin dung lượng lớn (Large Payload): Kafka được tối ưu hóa cực đoan cho hàng triệu tin nhắn nhỏ (thường chỉ vài Kilobytes). Nếu bạn nhồi nhét các tệp video, file PDF (hàng chục hay hàng trăm Megabytes) vào Kafka, nó sẽ làm "nghẹn" card mạng, thổi bay vùng nhớ đệm hệ điều hành (OS Page Cache) và làm chậm toàn bộ hệ thống.
-
⚖️ Hệ thống quy mô nhỏ (Small-scale projects): Vận hành một cụm Kafka đòi hỏi chi phí phần cứng lớn và một đội ngũ kỹ sư hiểu sâu về hệ thống để bảo trì, tinh chỉnh (tuning). Nếu ứng dụng của bạn chỉ loanh quanh vài nghìn tin nhắn mỗi ngày, việc dựng Kafka chẳng khác nào dùng "dao mổ trâu để giết gà".
Như vậy, chúng ta đã hoàn tất chuyến hành trình "giải phẫu" Apache Kafka, từ việc mổ xẻ từng đoạn mã Zero-copy dưới tầng đáy hệ điều hành, cho đến việc chiêm ngưỡng mạng lưới phân tán khổng lồ trải dài qua nhiều trung tâm dữ liệu. Rõ ràng, Kafka không chỉ là một công cụ truyền tin. Nó là một cỗ máy thời gian vô hình, một cuốn nhật ký bất diệt ghi lại nhịp đập của toàn bộ doanh nghiệp theo thời gian thực.
Thế nhưng, sức mạnh vĩ đại luôn đi kèm với cái giá phải trả là sự phức tạp tột độ trong vận hành.
Đừng mang một lưỡi cưa máy khổng lồ đi cắt một quả táo. Nếu hệ thống của bạn chỉ có vài ngàn người dùng, hoặc bạn chỉ cần một "người đưa thư" đơn giản để giao việc ngầm (Background Task Queue) cho ứng dụng web, thì việc dựng lên một cụm Kafka chẳng khác nào xây một hệ thống đường sắt cao tốc chỉ để đi giao một chiếc bánh pizza. Trong những trường hợp đó, sự gọn nhẹ của RabbitMQ hay Redis Pub/Sub mới là chân ái.
Kafka sinh ra là để gánh vác thế giới ngầm hỗn loạn của những siêu dữ liệu, nơi mà sự mất mát là không thể dung thứ và tốc độ tính bằng phần nghìn giây.
Vậy còn bạn? Hãy nhìn lại bức tranh kiến trúc mà đội ngũ của bạn đang xây dựng, hay chính những ứng dụng bạn đang dùng hàng ngày: Liệu bài toán dữ liệu đó đang cần sự linh hoạt của một "người đưa thư" nhanh nhẹn, hay đang khao khát sức mạnh của một "hệ thần kinh trung ương" bất diệt mang tên Kafka?
All rights reserved
