Deep into Transaction
Hầu như tất cả những ai đọc bài này hẳn cũng biết transaction sinh ra để làm gì, đó là: Đảm bảo 1 process được thực hiện hoàn chỉnh từ bước đầu đến bước cuối, rollback trạng thái dữ liệu nếu xảy ra lỗi trong quá trình thực thi. Xoay quanh chủ đề này có nhiều vấn đề đáng bàn tới, nên bài viết này sẽ đi đào sâu thêm về khía cạnh có thể khiến chủ đề thêm phần thú vị.
1. The Slippery Concept of a Transaction
Cuối những năm 2000, NoSQL DB bắt đầu phổ biến, hướng tới đưa ra 1 sự lựa chọn về data model bằng cách thêm vào replication và partitioning. Transaction là một thay đổi chính trong bước chuyển dịch này, thế hệ DB mới hầu như bỏ luôn transaction, hoặc 1 số khác đưa ra tập điều kiện nhỏ hơn.
Dưới sự bùng nổ của các hệ thống phân tán, nảy sinh hai luồng quan điểm: bỏ transaction để đảm bảo hiệu suất hoặc xây dựng 1 ứng dụng nghiêm túc và có giá trị. Đây thực ra là 1 quyết định technical design, phải lựa chọn trade-off thích hợp với yêu cầu hệ thống đưa ra. Trade-off đó như thế nào thì đi tiếp nhá.
1.1 ACID
Tính ACID có thể hiểu vắn tắt là:
Atomicity
Tính nguyên tử - Hoặc là thực hiện hết, hoặc là không thực hiện
Consitency
Đặc tính này thiên về duy trì 1 dữ liệu nhất quán và có nghĩa. AID là đặc tính của database, trong đó thì C lại là đặc tính của application. 1 App có thể phụ thuộc vào đặc tính Atomic và Isolation của DB để đạt được tính Consitency, nhưng không thể chỉ phụ thuộc vào mỗi database.
Isolation
Tính độc lập của 1 transaction, tức nó không thể bị can thiệp bởi 1 transaction khác
Durability
Có khả năng lưu trữ data an toàn, kể cả trong trường hợp lỗi phần cứng hoặc DB crash.
Đối với single-node DB, điều đó có nghĩa là data được lưu giữ xuống 1 nonvolatile storage như là HDD hoặc SSD. Thường đi kèm cơ chế write-ahead log, giúp recovery envent đang dở chừng. Trong 1 replicated database, đặc tính này có nghĩa là dữ liệu đã được replicate xong.
1.2 Single Object và Multi Object Operation
Single và Multi ở đây nói về số lượng record tác động lên Đối với Single Object, đây chắc chắn là điều mà tất cả các DB cần đảm bảo. Tưởng tượng 1 record có 5 field, trong đó có 2 field được update và 3 field không. Vậy 1 record vừa đúng vừa sai như vậy có ý nghĩa gì không? Chắc chắn không. Chúng sẽ xử lý bằng cách
- Tính Atomicity có thể được thực hiện bằng cách sử dụng log phục hồi sau sự cố BTree
- Tính Isolation có thể được thực hiện bằng khóa trên từng đối tượng, đảm bảo chỉ một luồng truy cập vào đối tượng đó tại một thời điểm Một số cơ sở dữ liệu còn cung cấp các atomic operation nâng cao, chẳng hạn như:
- Increment: Giúp tránh vòng lặp đọc-sửa-ghi hoặc 1 giải pháp tương tự là Compare-and-set: Chỉ ghi dữ liệu nếu giá trị chưa bị thay đổi bởi một client khác
Tính cần thiết của multi object transaction
Nhiều distributed datastore loại bỏ multi object transaction vì nó khó để triển khai trên các parition. Ở đây chúng ta sẽ không nói về distributed transaction, đây sẽ là vấn đề chúng ta sẽ thảo luận trong post sau. Ờ thì tại sao chúng ta còn cần quan tâm tới multi object operation, liệu single operation có đủ? Thử trả lời những câu hỏi sau:
- Trong relational DB, khi thêm nhiều record mà các record có mối quan hệ khoá ngoại, khi thêm vào chúng ta cũng mong muốn các mối quan hệ này ... valid, nếu không thì dữ liệu non-sense
- Trong cơ sở dữ liệu document, những field được update cùng nhau thường trong 1 document/1 single object. Tuy nhiên do thiếu chức năng JOIN, denormalization được khuyến khích
- Trong DB có secondary index(hầu hết các DB trừ các DB chỉ có key-value thuần tuý), index là các đối tượng độc lập trong cơ sở dữ liệu, cần đảm bảo chúng được update đầy đủ cùng với record.
2. Weak Isolation Level
2.1 Read Commited
Giúp loại bỏ 2 vấn đề:
- Đọc dơ: Đọc 1 dữ liệu chưa được commit
![image.png]()
- Ghi dơ: Ghi đè 1 dữ liệu chưa được commit
![image.png]()
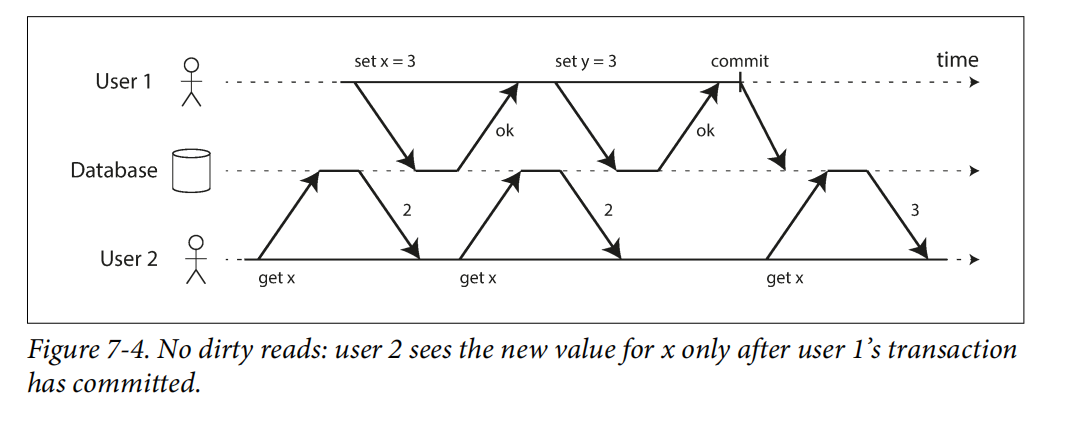
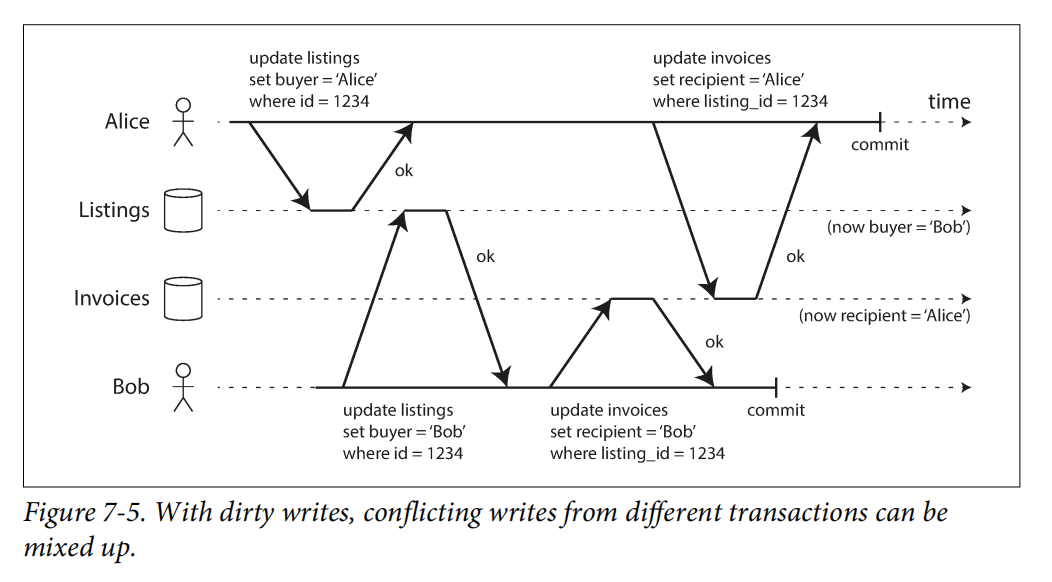
Cách triển khai:
Đối với ghi dơ: Hầu hết db sử dụng row-level lock. Khi write, transaction sẽ acquire 1 lock trên object cần xử lý.
Đối với đọc dơ:
- Option 1: Sử dụng row-level lock giống trên, khi read thì sẽ acquire lock, xong nhả ngay sau khi đọc xong. Tuy nhiên trong 1 lần write, có khả năng block rất nhiều tác vụ đọc -> giảm hiệu suất
- Option 2: Cho mỗi object đang được ghi, lưu cả giá trị cũ và mới -> transaction khác có thể đọc dữ liệu cũ. Cách này phù hợp hơn trong thực tế.
2.2 Snapshot Isolation và Repeatable read
 Read skew khác với non-repeatable read ở chỗ nó ảnh hưởng trên nhiều object. Ở ví dụ trên, tổng tiền của Alice ở 2 tài khoản ban đầu là 1000, nhưng ở phía Alice khi truy vấn số dư của cả 2 tài khoản tổng lại đang là 900.
Read skew khác với non-repeatable read ở chỗ nó ảnh hưởng trên nhiều object. Ở ví dụ trên, tổng tiền của Alice ở 2 tài khoản ban đầu là 1000, nhưng ở phía Alice khi truy vấn số dư của cả 2 tài khoản tổng lại đang là 900.
Điều này có thể khiến Alice vô cùng bối rối. Điều này vẫn tuân thủ hoàn toàn với Read commited, số dư của Alice ở tài khoản 1 được đọc trước transaction commit, số dư ở tài khoản 2 được đọc sau khi transaction commit.
Sự không nhất quán này có thể nhanh chóng biến mất sau khi Alice truy vấn lại (đóng mở app).
Một số khác thì tạo thành vấn đề thực sự:
- Trong trường hợp backup, có thể khiến dữ liệu ở trạng thái sai lệch sau khi khôi phục
- Trường hợp chạy query trên 1 phần lớn của db, cho mục đích phân tích dữ liệu hoặc kiểm tra tính toàn vẹn của dữ liệu Snapshot isolation là giải pháp phổ biến cho read skew. Ý tưởng là mỗi transaction đọc 1 phiên bản nhất quán của db, nó thấy được tất cả dữ liệu commited trong db từ lúc start transaction và chỉ sử dụng dữ liệu đó.
Cách triển khai snapshot isolation
Từ khía cạnh cải thiện performance, key principle là readers không block writers và ngược lại. Technique được sử dụng là MVCC(Multi-version concurency control).
Quay lại bài toán ban đầu, transaction 12 sẽ đọc những dữ liệu có version mới nhất <= 12, nên nó sẽ đọc ra số dư tài khoản tại thời điểm cũ là 500 + 500 = 1000 -> Bài toán ban đầu được giải quyết. Field deleted_by sẽ đánh dấu là dữ liệu đó đã bị xoá bởi ID của transaction request xoá. Nếu xác định rằng không có transation nào sử dụng dữ liệu xoá, garbage collector sẽ thu thập đám dữ liệu đó.
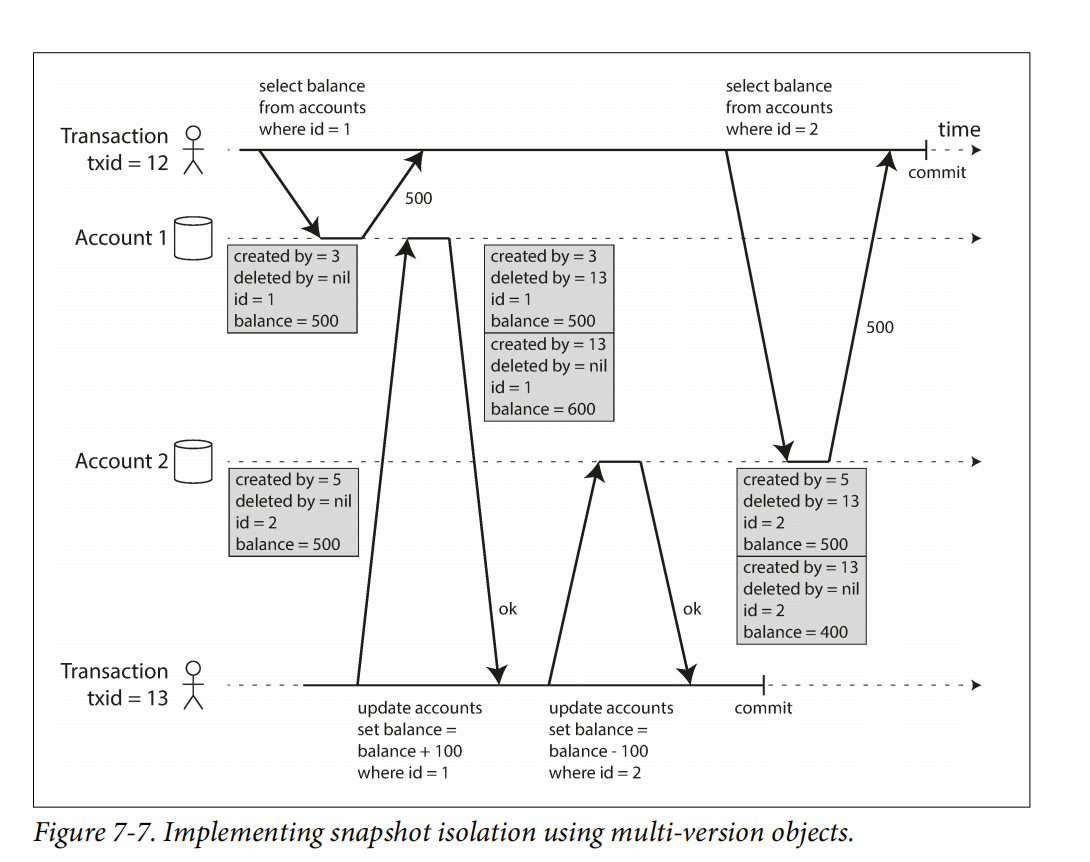
Snapshot isolation maintain index bằng cách đánh thêm index cho tất cả các phiên bản hoặc Append-Only-BTree. (...)
Repeatable Read và sự nhầm lẫn về tên gọi
Snapshot Isolation (SI) là một mức cách ly quan trọng, nhưng các hệ quản trị CSDL gọi nó khác nhau: Oracle gọi là Serializable, trong khi PostgreSQL & MySQL gọi là Repeatable Read. Nguyên nhân là do SQL Standard không có khái niệm Snapshot Isolation, vì nó dựa trên định nghĩa từ System R (1975), trước khi SI ra đời.
SQL định nghĩa Repeatable Read, nhưng quá mơ hồ, dẫn đến mỗi CSDL triển khai khác nhau. IBM DB2 thậm chí dùng "Repeatable Read" để chỉ Serializability, gây thêm nhầm lẫn. Kết quả là không ai thực sự biết "Repeatable Read" nghĩa là gì nếu không kiểm tra từng hệ thống cụ thể.
2.3 Preventing Lost Updates
Lost update problem, a read-modify-write cycle 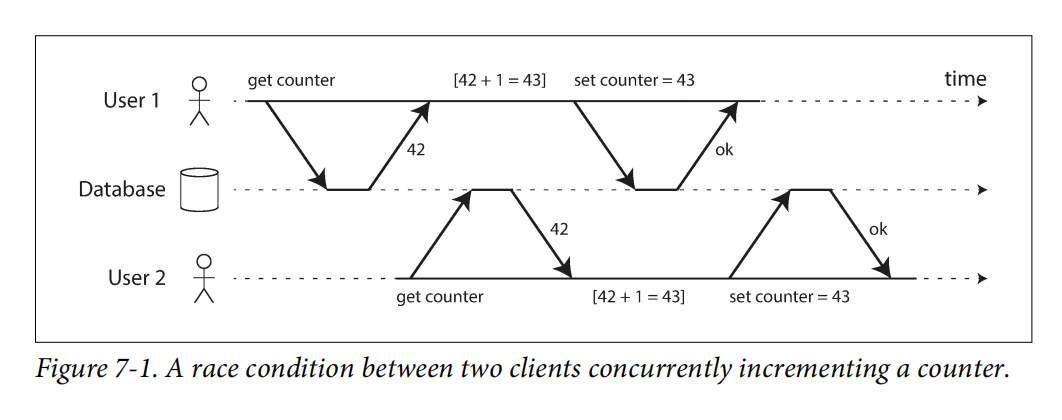
Atomic write operations
Thường tạo 1 exclusive lock để khoá trên object nó đang thay đổi, đảm bảo không transaction nào được đọc cho đến khi transaction hiện tại ghi xong
Explicit locking
Được dùng tới trong trường hợp atomic operation sẵn có trong db không cung cấp đủ tính năng cần thiết. SELECT FOR UPDATE
Tự động phát hiện lost updates
Thay vì dùng khóa như 2 cách ở trên để ép giao dịch chạy tuần tự, một cách tiếp cận khác là cho phép chạy song song và nếu phát hiện mất cập nhật, hệ thống hủy giao dịch và yêu cầu thử lại. Cách này hoạt động tốt với
Snapshot Isolation (SI) và được hỗ trợ trong PostgreSQL, Oracle, SQL Server, nhưng MySQL/InnoDB không phát hiện mất cập nhật, khiến một số tác giả sách cho rằng nó không cung cấp SI thực sự. Phát hiện mất cập nhật tự động giúp giảm lỗi lập trình và đảm bảo tính nhất quán dữ liệu mà không cần khóa thủ công.
Compare and Set
-- This may or may not be safe, depending on the database implementation (tức là nếu db không lưu trữ lại old snapshot thì chịu =]] )
UPDATE wiki_pages SET content = 'new content'
WHERE id = 1234 AND content = 'old content';
Conflict resolution và replication
Trong cơ sở dữ liệu sao chép, việc ngăn Lost Update khó hơn vì dữ liệu có thể ghi đồng thời trên nhiều node.
Khóa và compare-and-set không hiệu quả trong multi-leader hoặc leaderless replication 📌 Giải pháp phổ biến:
- ✅ Tạo nhiều phiên bản xung đột (siblings) và dùng ứng dụng hoặc cấu trúc dữ liệu đặc biệt để gộp và xử lý sau.
- ✅ Dùng commutative operations như increment counter hoặc add to set, đảm bảo kết quả đúng dù áp dụng theo thứ tự khác nhau. (Riak 2.0 áp dụng cách này để ngăn lost updates VD: Người dùng X nhấn thích trên node A → A ghi +1 vào biến đếm. Người dùng Y nhấn thích trên node B → B ghi +1 vào biến đếm. Khi đồng bộ, hai phép cộng được gộp lại → Tổng chính xác là 102.
- ⚠️ "Last Write Wins" (LWW) – phương pháp ghi đè dữ liệu xung đột bằng giá trị mới nhất – dễ gây mất cập nhật, nhưng lại là mặc định trong nhiều hệ thống sao chép. 🚨
2.4 Write Skew và Phantoms (To be continued)
3. Serializability (To be continued)
All rights reserved
