Cuộc chiến API Scraping tốt nhất 2026: Top 10 lựa chọn của kỹ sư
"Cấu trúc trang web lại thay đổi rồi..."
Vào sáng thứ hai, bạn đã bao giờ rơi vào tuyệt vọng với câu nói đó chưa? Kịch bản Python vất vả viết tuần trước giờ không chạy được nữa. Lạc lối trong mê cung của Cloudflare, và những ngày tháng chiến đấu không hồi kết với IP BAN...
Thành thật mà nói, ngày xưa tôi cực kỳ ghét web scraping.
Nhưng đến năm 2026, bối cảnh đã hoàn toàn thay đổi. Giờ đây không còn đơn thuần là "GET HTML" nữa. Việc tránh nhận diện dấu vân tay bằng AI, và quan trọng hơn cả là nhu cầu bùng nổ về dữ liệu có cấu trúc để "nhồi dữ liệu sạch cho LLM (Mô hình ngôn ngữ lớn)" đã thay đổi luật chơi.
Hôm nay, tôi sẽ giới thiệu top 10 công cụ trích xuất dữ liệu tốt nhất năm 2026, dựa trên trải nghiệm thực tế của tôi, không chút thiên vị.
Bảng so sánh nhanh cho người bận rộn
Dành cho các kỹ sư bận rộn, đây là kết luận. Hãy chọn công cụ phù hợp với tình hình hiện tại của bạn:
| Tên công cụ | Đánh giá của tôi (trong một câu) | Tính năng sát thủ năm 2026 | Độ đề xuất |
|---|---|---|---|
| Bright Data | Nếu tiền không phải vấn đề thì chọn cái này | Trang bị tiêu chuẩn cho doanh nghiệp để tránh mọi rủi ro | ⭐⭐⭐⭐⭐ |
| Firecrawl | Cứu tinh cho nhà phát triển LLM | Chuyển đổi Web trực tiếp sang Markdown (Bắt buộc cho RAG) | ⭐⭐⭐⭐⭐ |
| Oxylabs | Bỏ qua nỗi lo phân tích cú pháp | AI tự động chuyển đổi thành JSON | ⭐⭐⭐⭐ |
| ScrapingBee | Render JS dễ dàng | Giải phóng khỏi việc quản lý Headless Browser | ⭐⭐⭐⭐ |
| Apify | Lựa chọn không cần tự viết code | Chợ ứng dụng với hơn 1500 crawler "làm sẵn" | ⭐⭐⭐⭐ |
| ZenRows | Ngựa ô về hiệu suất trên giá thành | Khả năng chống chặn cao nhưng giá rẻ | ⭐⭐⭐⭐ |
| SerpApi | Chuyên gia kết quả tìm kiếm | Chuyển đổi kết quả tìm kiếm Google thành API sạch sẽ | ⭐⭐⭐⭐⭐ |
| Smartproxy | Thế mạnh về Proxy IP | Kết hợp hoàn hảo giữa Proxy dân cư và API | ⭐⭐⭐ |
| Browse AI | Dành cho người không chuyên kỹ thuật | Tạo bot chỉ bằng các cú click chuột | ⭐⭐⭐ |
| ScraperAPI | Đơn giản là nhất | Chỉ cần gửi 1 request mà không cần suy nghĩ nhiều | ⭐⭐⭐ |
Review chi tiết 10 công cụ sinh tồn năm 2026
Dưới đây, tôi sẽ đi sâu vào "cái gì hay ho" của từng công cụ dưới góc nhìn thực tế.
1. Bright Data: Nếu đắn đo thì chọn cái này (miễn là có ngân sách)
Gã khổng lồ trong ngành, Bright Data. Scraping Browser được phát hành năm 2026 thực sự là một vũ khí hủy diệt. Trước đây chỉ cần lo xoay vòng proxy, nhưng giờ đây việc đối phó với dấu vân tay trình duyệt (Fingerprint) là bắt buộc. Bright Data làm điều đó hoàn toàn tự động. Nó cung cấp môi trường thông qua API giống như con người đang thao tác trình duyệt, nên cảm giác như không bao giờ bị chặn.
- Trang chủ: Bright Data
2. Firecrawl: Tiêu chuẩn mới của kỷ nguyên AI
Cú sốc lớn nhất năm nay. Đây không chỉ là một công cụ scraping đơn thuần. Nó chuyên biệt để tạo ra "dữ liệu cho LLM ăn". Nó loại bỏ toàn bộ nhiễu như quảng cáo, thanh điều hướng, và trả về trang web dưới dạng Markdown sạch sẽ. Nếu bạn đang xây dựng ứng dụng RAG (Retrieval-Augmented Generation), đây là lựa chọn duy nhất.
- GitHub: mendableai/firecrawl
- Trang chủ: Firecrawl
3. Oxylabs: Chuyên gia dữ liệu có cấu trúc
"Muốn có dữ liệu nhưng ngại parse HTML". Oxylabs chính là chân ái cho những nhà phát triển "lười biếng" (theo nghĩa tích cực) như vậy. Bộ giải mã AI độc quyền của họ tự động hiểu các trang sản phẩm thương mại điện tử và trả về JSON. Ngay cả khi thiết kế trang web thay đổi, AI cũng linh hoạt thích ứng, giảm đáng kể chi phí bảo trì.
- Trang chủ: Oxylabs
4. ScrapingBee: Người bạn đồng hành trong kỷ nguyên SPA

Scraping các SPA (Single Page Application) được viết bằng React hay Vue mà tự host Puppeteer hay Playwright thì khá nặng nề đúng không? ScrapingBee sẽ gánh vác toàn bộ việc render phiền phức đó. Kể cả năm 2026, độ ổn định trong render JS của họ vẫn ở một đẳng cấp khác.
- Trang chủ: ScrapingBee
5. Apify: App Store của giới Crawler
Khi bạn nghĩ "Tôi muốn chức năng thu thập hashtag Instagram", hãy xem Apify trước khi tự viết code. Hầu hết đều có ai đó bán "Actor (Bot scraping làm sẵn)". Dù là Google Map hay TikTok, mượn giải pháp có sẵn thì thời gian phát triển bằng 0. Hệ sinh thái này thực sự hùng mạnh.
- Trang chủ: Apify
6. ZenRows: Ứng cử viên "Ngon - Bổ - Rẻ" sắp tới
Dù độ nhận diện chưa bằng các ông lớn, nhưng cá nhân tôi đang chú ý đến ZenRows. Sở hữu khả năng chống block ngang ngửa các ông lớn nhưng mức giá lại cực kỳ cạnh tranh. Đối với startup hoặc dự án cá nhân muốn "bắt đầu nhỏ", đây có thể là giải pháp tối ưu. Một trong những công cụ tăng trưởng nhanh nhất năm 2026.
- Trang chủ: ZenRows
7. SerpApi: Công cụ bắt buộc cho dân SEO
Nếu muốn phân tích kết quả tìm kiếm (SERP) của Google hay Baidu, không cần nhìn đi đâu khác. Họ JSON hóa các yếu tố SERP phức tạp như quảng cáo, local pack, knowledge graph một cách chính xác đáng kinh ngạc. Nếu tự làm tool monitoring SEO thì đây là mảnh ghép bắt buộc.
- Trang chủ: SerpApi
8. Smartproxy: Sự nghiêm túc của nhà cung cấp Proxy
Vốn nổi tiếng là nhà cung cấp proxy, nên chất lượng IP rất tốt. Phát huy giá trị thực sự khi cần vượt qua các nội dung giới hạn địa lý (Geo-blocking) khắt khe. Về khả năng đóng giả "cư dân của một quốc gia cụ thể", đúng là "trăm hay không bằng tay quen".
- Trang chủ: Smartproxy
9. Browse AI: Không biết code cũng không sao
"Tôi không biết lập trình nhưng muốn theo dõi giá đối thủ". Tôi đề xuất Browse AI cho các marketer như vậy. Chỉ cần dùng extension trình duyệt click "trích xuất chỗ này", bot scraping sẽ được tạo ra. Tính năng tự động đồng bộ sang Google Sheets cũng tiện lợi một cách bất ngờ.
- Trang chủ: Browse AI
10. ScraperAPI: Đơn giản là nhất
Khi muốn làm nhanh prototype, tôi chọn cái này không chút do dự. "Gửi API, nhận HTML". Không cần cài đặt thừa thãi. Việc xoay vòng proxy cũng được thực hiện ngầm toàn bộ. Đồng minh mạnh nhất trong giai đoạn đầu phát triển khi bạn "chỉ cần thứ gì đó chạy được".
- Trang chủ: ScraperAPI
Tóm lại, nên chọn thế nào?
Tiêu chuẩn lựa chọn của năm 2026 không phải là stack công nghệ mà nên dựa trên "mục đích".
- Phát triển Ứng dụng LLM / RAG: Không cần đắn đo, chọn Firecrawl. Xuất ra Markdown là chân lý.
- Hệ thống nghiệp vụ tuyệt đối không được dừng: Giải quyết bằng sức mạnh đồng tiền với Bright Data hoặc Oxylabs.
- MXH hoặc nền tảng đặc thù: Tìm kiếm trên store của Apify trước.
- Nghiên cứu thị trường cho người không chuyên: Tự động hóa no-code với Browse AI.
"Vũ khí thứ hai" để tăng tốc quy trình phát triển
Được rồi, giả sử bạn đã chọn xong công cụ scraping và "đã lấy được dữ liệu". Nhưng chưa xong đâu. Bản thân API scraping cũng là một "API", và bạn cũng cần phát triển API để đẩy dữ liệu thu thập được vào backend của mình đúng không?
Đó là lúc tôi dùng Apidog).
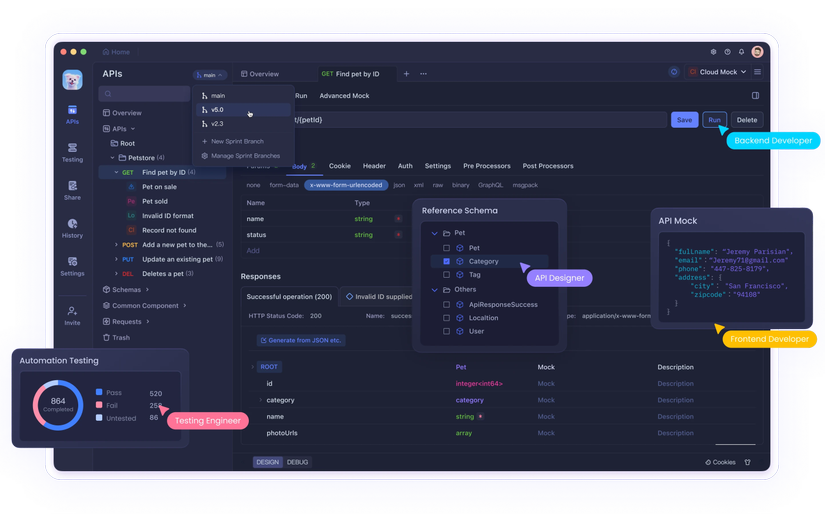
Tại sao lại là Apidog cho phát triển scraping?
-
Tránh lãng phí tiền (Debug): Nếu viết code chạy ngay, lỡ sai tham số gây lỗi thì vẫn bị tính phí request API (cái này thốn lắm). Dùng GUI của Apidog để thiết lập request kỹ càng, kiểm tra thông suốt rồi mới đưa vào code thì sẽ cắt giảm được chi phí thử sai vô ích.
-
Phát triển song song với Mock Server: Nếu đội scraping và đội frontend tách biệt, bạn có thể định nghĩa "phản hồi JSON mong đợi" trên Apidog và dựng Mock Server, việc phát triển ứng dụng có thể tiến hành mà không cần đợi implement xong việc thu thập dữ liệu. Tiết kiệm thời gian cực kỳ.
-
Tính năng sinh code: Sau khi kiểm tra hoạt động trên Apidog, bạn có thể sinh code Python hoặc Node.js chỉ bằng một cú click. Copy paste thẳng vào script của mình là xong. Quy trình này quá mượt mà.
Kết luận: "Rút dữ liệu" dùng Firecrawl/Bright Data, "Quản lý & Phát triển API" dùng Apidog. Sự kết hợp này là cấu hình chuẩn của tôi trong năm 2026.
Hy vọng hướng dẫn này sẽ giúp cuộc sống thu thập dữ liệu của bạn dễ thở hơn một chút. Nếu có câu hỏi như "Trang web này khó lấy quá" hay "Tool này dùng ổn không?", hãy chia sẻ trên mạng xã hội nhé. Cùng nhau tìm cách giải quyết nào!
All rights reserved
