Chọn Giải pháp Tối ưu cho Vector Database trong RAG
Trong hệ thống Retrieval-Augmented Generation (RAG), mình thấy rằng vector database đóng vai trò cực kỳ quan trọng trong việc lưu trữ và truy vấn các embeddings. Việc chọn đúng vector database sẽ ảnh hưởng trực tiếp đến tốc độ truy xuất cũng như chất lượng câu trả lời của hệ thống AI.
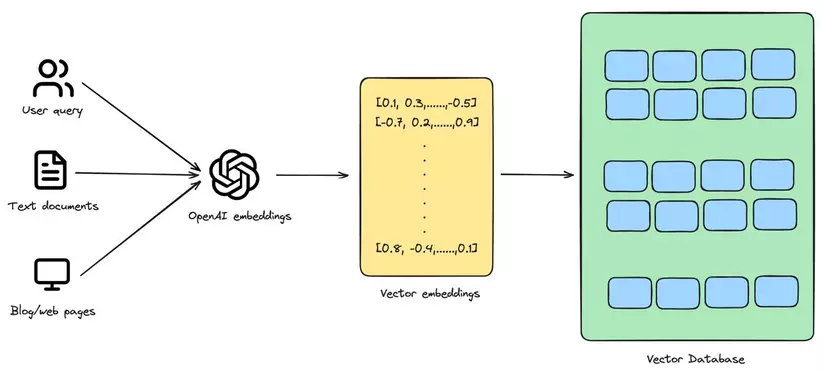
So sánh chi tiết các vector database
| Database | Ưu điểm | Nhược điểm |
|---|---|---|
| FAISS | - Hiệu suất cao với các thuật toán nén và chỉ mục đa dạng. - Tối ưu hóa cho GPU, phù hợp với truy vấn nhanh trên dữ liệu lớn. - Mã nguồn mở, dễ tích hợp. |
- Không hỗ trợ phân tán, khó mở rộng khi dữ liệu lớn. - Không có cơ chế cập nhật động; cần xây dựng lại chỉ mục khi dữ liệu thay đổi. |
| Annoy | - Nhẹ và dễ sử dụng. - Phù hợp cho các hệ thống nhúng hoặc khi cần truy vấn nhanh trong bộ nhớ RAM. - Không yêu cầu nhiều tài nguyên tính toán. |
- Không hỗ trợ cập nhật dữ liệu động. - Không tối ưu cho tập dữ liệu lớn như FAISS. |
| HNSWlib | - Cung cấp tìm kiếm nhanh với thuật toán HNSW. - Hỗ trợ cập nhật dữ liệu động, linh hoạt hơn FAISS. - Tối ưu hóa hiệu suất cho CPU. |
- Không hỗ trợ GPU. - Không có cơ chế phân tán tích hợp sẵn. |
| Weaviate | - Là một vector database mạnh mẽ, hỗ trợ phân tán. - Hỗ trợ tìm kiếm theo schema và tích hợp với GraphQL. - Hỗ trợ cập nhật dữ liệu động. |
- Yêu cầu tài nguyên cao hơn so với FAISS hoặc Annoy. - Cấu hình và quản lý phức tạp hơn. |
| Pinecone | - Dịch vụ quản lý, không cần lo lắng về hạ tầng. - Hỗ trợ cập nhật dữ liệu động và mở rộng linh hoạt. - Dễ dàng tích hợp với các hệ thống AI/ML. |
- Dịch vụ có phí, không phù hợp cho các dự án nhỏ hoặc nghiên cứu cá nhân. - Ít khả năng tùy chỉnh so với các giải pháp mã nguồn mở. |
| Elasticsearch | - Hỗ trợ tìm kiếm full-text kết hợp với tìm kiếm vector. - Dễ dàng mở rộng và phân tán. - Cộng đồng lớn và tài liệu phong phú. |
- Hiệu suất tìm kiếm vector chưa tối ưu như các giải pháp chuyên dụng như FAISS. - Cấu hình phức tạp và yêu cầu tài nguyên cao. |
| PostgreSQL (pgvector) | - Dễ dàng tích hợp với các ứng dụng hiện có. - Hỗ trợ ACID, đảm bảo tính toàn vẹn của dữ liệu. - Mã nguồn mở và có cộng đồng hỗ trợ lớn. |
- Chưa được tối ưu cho truy vấn vector lớn. - Hiệu suất thấp hơn so với các giải pháp chuyên dụng. |
Dựa trên thông tin từ nguồn Superlinked
Lựa chọn phù hợp cho bài toán RAG
Dựa trên kinh nghiệm cá nhân, mình nhận thấy rằng việc lựa chọn vector database phù hợp cho hệ thống Retrieval-Augmented Generation (RAG) phụ thuộc vào nhiều yếu tố như quy mô dữ liệu, yêu cầu hiệu suất, khả năng mở rộng và tích hợp với hệ thống hiện có. Dưới đây là một số gợi ý chi tiết:
Dữ liệu nhỏ, truy vấn nhanh
-
Annoy: Phù hợp cho các ứng dụng cần tìm kiếm nhanh với bộ dữ liệu nhỏ và không yêu cầu cập nhật thường xuyên. Annoy xây dựng cây chỉ mục trên đĩa, giúp tiết kiệm bộ nhớ nhưng không hỗ trợ cập nhật động; do đó, khi dữ liệu thay đổi, cần phải tái tạo lại chỉ mục.
-
HNSWlib: Thích hợp cho các hệ thống yêu cầu truy vấn nhanh và hỗ trợ cập nhật dữ liệu động. HNSWlib sử dụng thuật toán đồ thị nhỏ gọn phân cấp (Hierarchical Navigable Small World) để cung cấp tìm kiếm gần đúng hiệu quả. Tuy nhiên, nó không hỗ trợ GPU và không có cơ chế phân tán tích hợp sẵn.
Dữ liệu lớn, cần GPU tối ưu
- FAISS: Lựa chọn hàng đầu khi làm việc với bộ dữ liệu lớn và cần hiệu suất truy vấn cao. FAISS được phát triển bởi Facebook AI Research, hỗ trợ GPU và cung cấp nhiều thuật toán nén và chỉ mục đa dạng. Tuy nhiên, FAISS không hỗ trợ phân tán và việc cập nhật dữ liệu đòi hỏi tái tạo lại chỉ mục, điều này có thể gây khó khăn khi dữ liệu thay đổi thường xuyên.
Hệ thống phân tán, mở rộng linh hoạt
-
Weaviate: Phù hợp cho các ứng dụng yêu cầu khả năng mở rộng và phân tán. Weaviate là một vector database mã nguồn mở, hỗ trợ tìm kiếm theo schema và tích hợp với GraphQL. Nó cung cấp cơ chế cập nhật dữ liệu động và khả năng mở rộng theo chiều ngang. Tuy nhiên, việc triển khai và quản lý Weaviate có thể phức tạp và yêu cầu tài nguyên hệ thống đáng kể.
-
Elasticsearch: Thích hợp khi cần kết hợp giữa tìm kiếm full-text và vector. Elasticsearch là một công cụ tìm kiếm phân tán mạnh mẽ, hỗ trợ mở rộng linh hoạt. Mặc dù không được thiết kế chuyên biệt cho vector search, nhưng với các plugin và cấu hình phù hợp, Elasticsearch có thể xử lý các truy vấn vector hiệu quả. Tuy nhiên, hiệu suất tìm kiếm vector có thể không cao bằng các giải pháp chuyên dụng như FAISS.
Không muốn quản lý hạ tầng
- Pinecone: Dành cho những ai muốn tập trung vào phát triển ứng dụng mà không muốn quản lý hạ tầng. Pinecone là dịch vụ vector database được quản lý hoàn toàn, cung cấp khả năng mở rộng linh hoạt và hỗ trợ cập nhật dữ liệu động. Tuy nhiên, đây là dịch vụ có phí và có thể hạn chế về khả năng tùy chỉnh so với các giải pháp mã nguồn mở.
Cần tích hợp với hệ thống dữ liệu truyền thống
- PostgreSQL (pgvector): Lựa chọn tốt khi cần tích hợp chức năng tìm kiếm vector vào hệ thống sử dụng PostgreSQL. Tiện ích mở rộng pgvector cho phép lưu trữ và truy vấn vector trong PostgreSQL, giúp dễ dàng tích hợp với các ứng dụng hiện có. Tuy nhiên, hiệu suất truy vấn vector có thể không cao bằng các giải pháp chuyên dụng, đặc biệt khi làm việc với bộ dữ liệu lớn.
Kết
Việc lựa chọn vector database phù hợp cần xem xét kỹ lưỡng các yếu tố về quy mô dữ liệu, yêu cầu hiệu suất, khả năng mở rộng và tích hợp với hệ thống hiện tại. Mỗi giải pháp đều có ưu và nhược điểm riêng, do đó, việc đánh giá và thử nghiệm thực tế sẽ giúp bạn đưa ra quyết định tối ưu cho hệ thống RAG của mình.
Đặc biệt, dựa vào hệ thống hiện có bạn đã xây dựng, bạn nên tận dụng lại những gì mình có để tối ưu chi phí và tài nguyên hệ thống.
VD trong trường hợp của mình, đã build cả cụm cluster Elasticsearch, cụm cluster database Postgres, thì mình sẽ không đi tìm một database và dựng lại toàn bộ từ đầu. Nhưng nếu làm từ đầu, mình sẽ FAISS của Mark một cơ hội 😆
Bạn nghĩ sao về ý kiến này, hãy cùng thảo luận nhé.
/Son Do
All rights reserved
