10 Công cụ Mã nguồn mở để Xây dựng AI Agent Local cấp Production năm 2026: Tạm biệt các API giá "cắt cổ"
AI ngày càng mạnh mẽ và tiện dụng. Nhưng "dùng thì sướng, trả tiền thì rát". Bộ nhớ đệm ngữ cảnh (context caching), cơ chế tự động thử lại (auto-retry) và các chuỗi suy luận phức tạp — mỗi bước đều "đốt" một lượng lớn Token.
Những developer thông minh đang tìm đến các công cụ AI mã nguồn mở để tự chủ công nghệ và đạt được chi phí biên bằng không (zero marginal cost). Với quá nhiều lựa chọn hiện có, chẳng việc gì phải "khô máu" với OpenAI hay Anthropic cả.

Hệ sinh thái mã nguồn mở hiện tại đã đủ trưởng thành để thay thế hoàn toàn các API trả phí, bao phủ toàn bộ quy trình từ suy luận (inference), RAG, điều phối (orchestration), đánh giá (evaluation) đến xử lý đa phương thức.
Dưới đây là 10 công cụ mã nguồn mở giúp bạn xây dựng các Agent cấp production. Chúng cho phép developer dựng các pipeline AI hoàn chỉnh ngay trên máy local hoặc server đám mây riêng, và mỗi công cụ đều sở hữu hơn 10.000 sao trên GitHub 🌟.
1. vLLM
Nếu Ollama dành cho developer "nếm thử" AI trên laptop, thì vLLM sinh ra là để phục vụ khả năng chịu tải cao (high concurrency) trong môi trường production. Công nghệ cốt lõi của nó là PagedAttention, một thuật toán quản lý bộ nhớ GPU lấy cảm hứng từ bộ nhớ ảo của hệ điều hành. vLLM giúp giảm đáng kể sự phân mảnh bộ nhớ, cho phép xử lý Batch Size lớn hơn nhiều trên cùng một phần cứng.
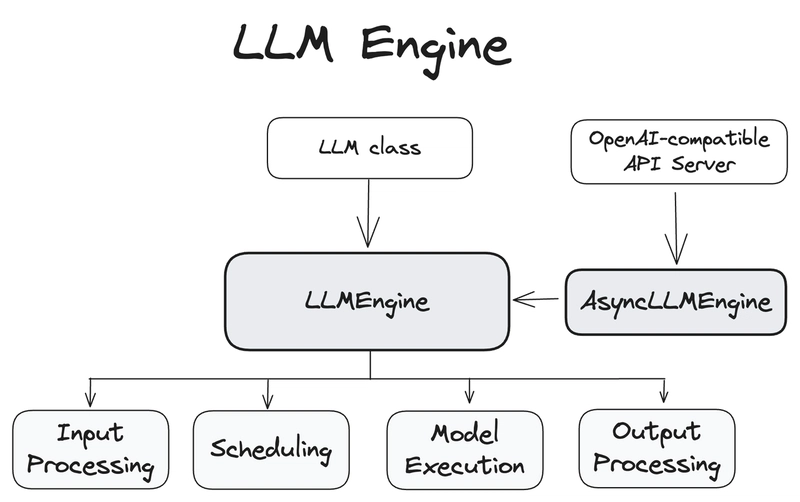
Đối với các kịch bản cần triển khai các mô hình lớn như Qwen2.5 hay Llama 3, thông lượng (throughput) của vLLM thường cao hơn vài lần so với thư viện tiêu chuẩn của HuggingFace. Nó hỗ trợ Continuous Batching (Xử lý lô liên tục), nghĩa là hệ thống không cần đợi cả lô hoàn thành mới chèn request mới vào, giúp giảm độ trễ dịch vụ đáng kể.
2. Ollama
Ollama giải quyết bài toán "khó triển khai". Nó đóng gói trọng số mô hình, cấu hình và prompt template thành một Modelfile duy nhất, giúp việc chạy LLM trở nên cực kỳ đơn giản. Nó hỗ trợ rất tốt các mô hình lượng tử hóa (định dạng GGUF), giúp chạy được các model 7B hay 14B tham số trên GPU không chuyên hoặc thậm chí là môi trường thuần CPU.
ServBay hiện đã hỗ trợ tính năng Cài đặt Ollama chỉ với một cú click. Bạn không cần lo lắng về các dependency dòng lệnh hay cấu hình biến môi trường phức tạp; có thể hoàn tất việc triển khai và khởi động dịch vụ Ollama ngay trong giao diện quản lý của ServBay.
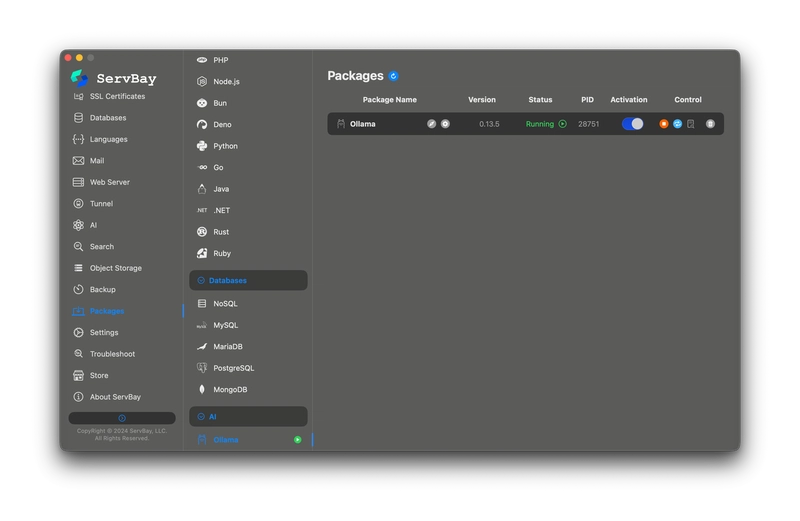
Kết hợp với API tương thích chuẩn OpenAI của nó, việc sử dụng "ServBay + Ollama" làm backend suy luận là một lựa chọn chi phí bảo trì cực thấp cho các công cụ nội bộ quy mô vừa và nhỏ.
3. LiteLLM
LiteLLM bản thân nó không chạy model; nó là một thư viện I/O và proxy server đa năng. Khi backend hệ thống của bạn vừa có API OpenAI, vừa có vLLM deploy local, lại còn có cả endpoint của Azure, việc bảo trì code sẽ là một cơn ác mộng.
LiteLLM cung cấp một giao diện thống nhất. Bạn chỉ cần gửi request theo định dạng của OpenAI, nó sẽ chịu trách nhiệm định tuyến (route) request đó đến Ollama, vLLM hoặc hơn 100 backend hỗ trợ khác. Nó đi kèm với tính năng cân bằng tải (load balancing), cơ chế dự phòng (fallback), và ghi lại chi phí cũng như độ trễ của từng cuộc gọi. Đây là chất keo kết dính để xây dựng kiến trúc đám mây lai (hybrid cloud).
4. CrewAI
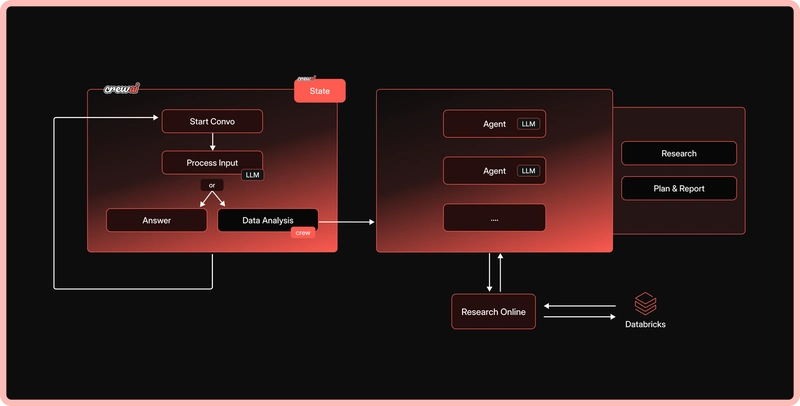
Hiện nay có rất nhiều framework Agent, nhưng CrewAI nổi bật với đặc điểm Nhập vai (Role-Playing). Nó không chỉ yêu cầu model thực hiện nhiệm vụ; nó cho phép developer định nghĩa "Vai trò", "Mục tiêu" và "Tiểu sử nhân vật" (Backstory).

Ví dụ, bạn có thể định nghĩa một Agent "Nhà nghiên cứu cấp cao" chịu trách nhiệm tìm kiếm thông tin, và một Agent "Cây viết kỹ thuật" chịu trách nhiệm tổng hợp thành bài viết. CrewAI sẽ tự động quản lý hội thoại và phân công nhiệm vụ giữa các agent này. Được xây dựng dựa trên LangChain nhưng đóng gói các quy trình điều khiển phức tạp, nó rất phù hợp để xây dựng các workflow cần suy luận nhiều bước.
5. Continue.dev
Đây là một plugin mã nguồn mở cho VS Code và JetBrains IDE, được thiết kế để thay thế GitHub Copilot. Ưu điểm cốt lõi của nó là hoàn toàn offline và không phụ thuộc vào model cụ thể (model-agnostic). Developer có thể kết nối nó với Ollama hoặc vLLM đang chạy local, sử dụng các model như DeepSeek-Coder hay CodeLlama để hoàn thành code và refactor.
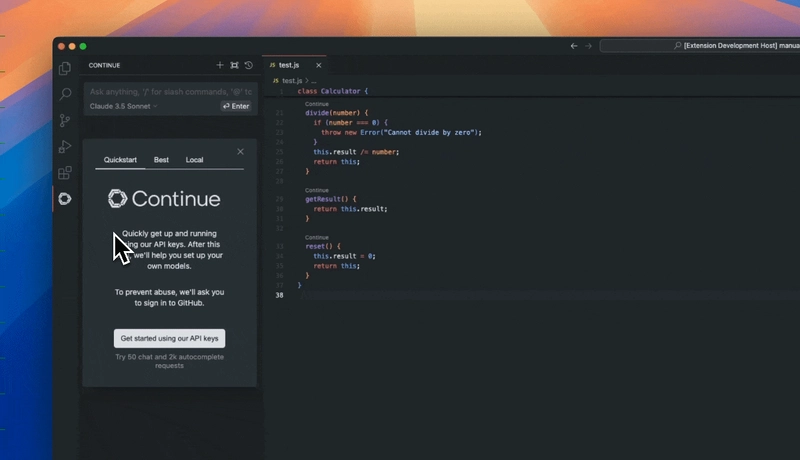
Đối với doanh nghiệp, điều này có nghĩa là mã nguồn cốt lõi không bao giờ cần upload lên đám mây, loại bỏ rủi ro rò rỉ. Nó hỗ trợ tham chiếu các file trong codebase thông qua ký tự @ làm ngữ cảnh, giúp model local cũng có thể hiểu được toàn bộ cấu trúc dự án.
6. Qdrant
Qdrant là một cơ sở dữ liệu vector hiệu năng cao được viết bằng Rust. Khác với database truyền thống, nó được thiết kế để lưu trữ và tìm kiếm các vector nhiều chiều. Trong các hệ thống Agent, nó đóng vai trò là nơi lưu trữ bộ nhớ dài hạn (long-term memory).

Đặc điểm của Qdrant là hỗ trợ tìm kiếm có lọc (HNSW + Filtering), cho phép developer áp dụng các điều kiện WHERE giống SQL song song với tìm kiếm ngữ nghĩa (ví dụ: tìm tài liệu liên quan đến "năm 2025" VÀ "trạng thái là đã xuất bản"). Điều này cực kỳ quan trọng để truy xuất chính xác trong môi trường production.
7. AnythingLLM
Nếu bạn không muốn viết code dựng pipeline RAG từ đầu, AnythingLLM hiện là công cụ "mì ăn liền" (out-of-the-box) hoàn thiện nhất. Nó là một ứng dụng desktop full-stack (có cả bản Docker), tích hợp sẵn vector database, embedding model và giao diện LLM.
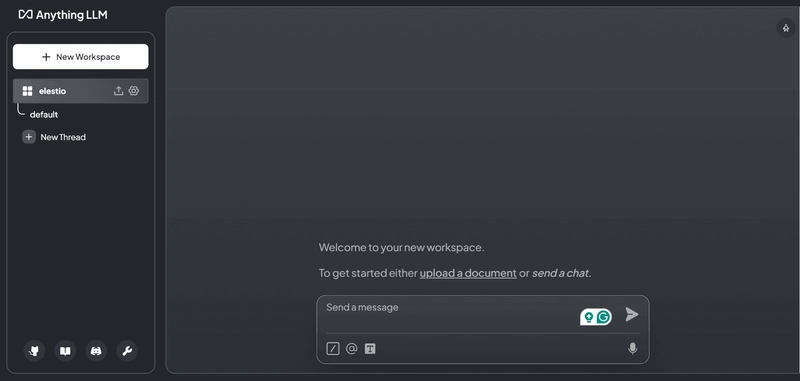
Người dùng chỉ cần kéo thả file PDF, Markdown hoặc link web vào giao diện, nó sẽ tự động thực hiện phân mảnh (Chunking) và vector hóa. Nó thậm chí hỗ trợ quản lý quyền đa người dùng, rất thích hợp để dựng nhanh hệ thống hỏi đáp kiến thức nội bộ (Knowledge Base) cho team.
8. Promptfoo
Sau khi sửa Prompt hoặc đổi model, làm sao biết chất lượng câu trả lời của hệ thống không bị giảm sút? Dựa vào test thủ công bằng "cơm" thì vừa chậm vừa thiếu chính xác.
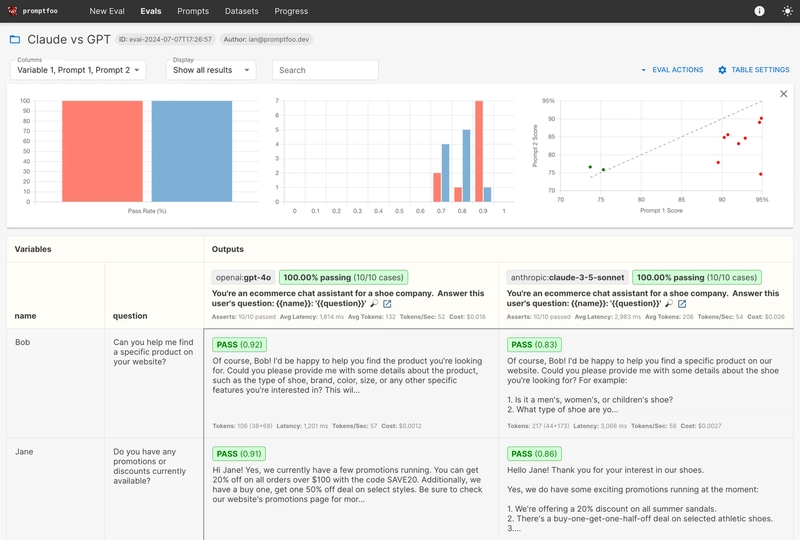
Promptfoo là một công cụ CLI tập trung vào việc đánh giá đầu ra của LLM. Developer có thể dùng nó để viết test case (giống như unit test), chạy hàng loạt các tổ hợp Prompt và Model khác nhau, rồi tự động chấm điểm. Nó có thể phát hiện xem đầu ra có chứa từ khóa cụ thể không, định dạng JSON có đúng không, thậm chí dùng một LLM khác để chấm điểm cho câu trả lời. Đây là "nhân viên kiểm soát chất lượng" (QA) trước khi đưa Agent lên production.
9. Diffusers
Trong lĩnh vực tạo sinh hình ảnh, thư viện Diffusers của Hugging Face là tiêu chuẩn thực tế. Nó cung cấp khả năng kiểm soát tầng thấp đối với các mô hình khuếch tán (diffusion models) như Stable Diffusion và Flux.

Khác với giao diện đồ họa như WebUI, Diffusers cho phép developer kiểm soát tinh vi từng bước của quá trình sinh ảnh qua code Python, ví dụ như thêm ControlNet để kiểm soát dáng, hoặc dùng LoRA để tinh chỉnh phong cách. Nếu Agent của bạn cần sinh ảnh, đây là thư viện nền tảng linh hoạt nhất.
10. Transformer.js
Không phải tác vụ AI nào cũng cần một backend Python khổng lồ. Transformer.js đã port thư viện transformers của Hugging Face sang môi trường JavaScript, hỗ trợ chạy model trực tiếp trên trình duyệt hoặc Node.js thông qua ONNX Runtime.

Đối với các tác vụ hạng nhẹ như phân loại văn bản, trích xuất từ khóa hay thậm chí nhận dạng giọng nói quy mô nhỏ (Whisper), chúng có thể được hoàn thành ngay tại phía client mà không cần gửi dữ liệu về server, giảm đáng kể độ trễ và chi phí máy chủ.
Quản lý hạ tầng Python và Node.js
Các công cụ trên cho thấy sức mạnh của stack AI mã nguồn mở, nhưng cũng có một vấn đề: phần lớn stack AI phụ thuộc sâu vào hệ sinh thái Python (như vLLM, CrewAI), trong khi một số khác lại cần môi trường Node.js (như Transformer.js).
Đây là lúc ServBay phát huy tác dụng như một công cụ quản lý môi trường phát triển thống nhất.
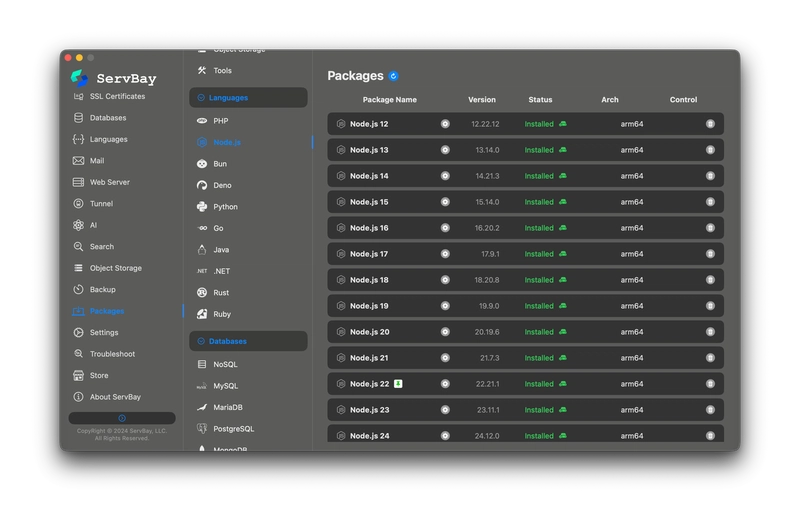
Vốn được thiết kế cho Web developer, nhưng cơ chế quản lý môi trường dạng sandbox của nó lại khớp hoàn hảo với nhu cầu phát triển AI.
- Cài đặt một chạm & Cùng tồn tại phiên bản: ServBay cho phép bạn cài đặt và chạy nhiều phiên bản Python và Node.js trên cùng một máy. Bạn có thể cấp Python 3.10 cho vLLM và Python 3.12 cho CrewAI mà không sợ chúng đánh nhau.
- Quản lý Node.js: Với các công cụ cần Node.js (như Transformer.js hay giao diện frontend), ServBay hỗ trợ chuyển đổi nhanh giữa các phiên bản mà không cần cấu hình
nvmphức tạp. - Tinh khiết & Cách ly: Tất cả môi trường của ServBay đều độc lập với hệ điều hành, không làm "ô nhiễm" thư viện hệ thống của macOS. Điều này đảm bảo tính ổn định lâu dài cho việc phát triển AI vốn thường xuyên phải cài đặt đủ loại gói pip.
Điều này cho phép developer cài đặt các stack AI khác nhau mà không lo làm hỏng môi trường hệ thống.
Lời kết
Việc chuyển dịch từ thuê năng lực tính toán trên mây về tự chủ dữ liệu tại local không chỉ là bài toán chi phí, mà còn là sự thể hiện quyền tự chủ công nghệ. Giờ đây, chúng ta đã sở hữu đủ các engine suy luận, framework điều phối, bộ nhớ lưu trữ và công cụ đánh giá để làm điều đó.
Tuy nhiên, đừng nghĩ "mã nguồn mở" đồng nghĩa với "sơ sài" hay "thiếu hỗ trợ". Nhiều công cụ như Qdrant, CrewAI, LiteLLM và Continue.dev, ngoài phiên bản open-source miễn phí, đều cung cấp các dịch vụ quản lý thương mại hoặc tính năng hỗ trợ doanh nghiệp (như SSO, Audit log, cam kết SLA).
Dùng những công cụ này rồi, mẹ sẽ không còn phải lo lắng về hóa đơn Token của bạn nữa.
All Rights Reserved
